Tour of Akka Cluster – Cluster Sharding
Contents
In Tour of Akka Cluster - Eventual consistency, persistent actors and message delivery semantics we started to look into making the reactive payment processor resilient to node crashes by exploring Akka Persistence, a mechansim that provides durability guarantees for actor state. We also briefly mentioned Akka Cluster Sharding which offers a way to automatically distribute actors of the same type over several nodes. In this article we are going to take a closer look at cluster sharding and then make use of it for our reactive payment processor.
Quite a few of the core ideas fueling Akka’s Cluster Sharding are to be found in the Pat Halland’s must-read paper Life beyond distributed transactions. For a technology that goes further in implementing those ideas, check out the Lagom Framework. I wrote about Lagom earlier and yet have to continue writing about it (in hindsight it looks like I got distracted by the birth of my son at that time). Lagom uses Akka Cluster Sharding below the hood, so let us have a look at that one first.
The primary design goal here is scale, more so than resilience against failure (even though that is a nice side-effect). In order to work fast with a lot of data, we need to hold the data in memory, and in order to scale, we need to distribute it accross nodes. Rather than trying to get distributed transactions to function correctly (which appears to be non-trivial both in theory and practice), the approach here is to employ transactions on the local scope only (where we know they work) and to combine message passing (with adequate semantics) for distributed communication. This is achieved by employing an architecture that separates scale-agnostic code (the one written by application developers) from scale-aware code (the one written by library developers):
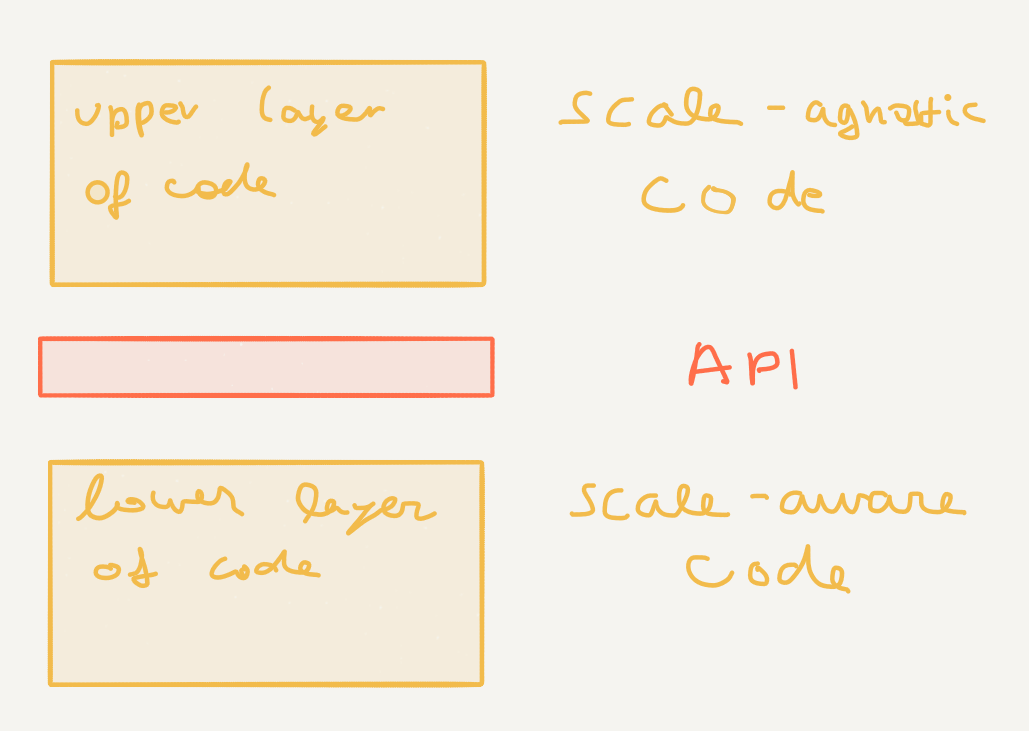
In other words, Akka Cluster Sharding exposes an API that allows us to work - for the most part - about scaling concerns. Let’s have a look at this API.
The Akka Cluster Sharding API
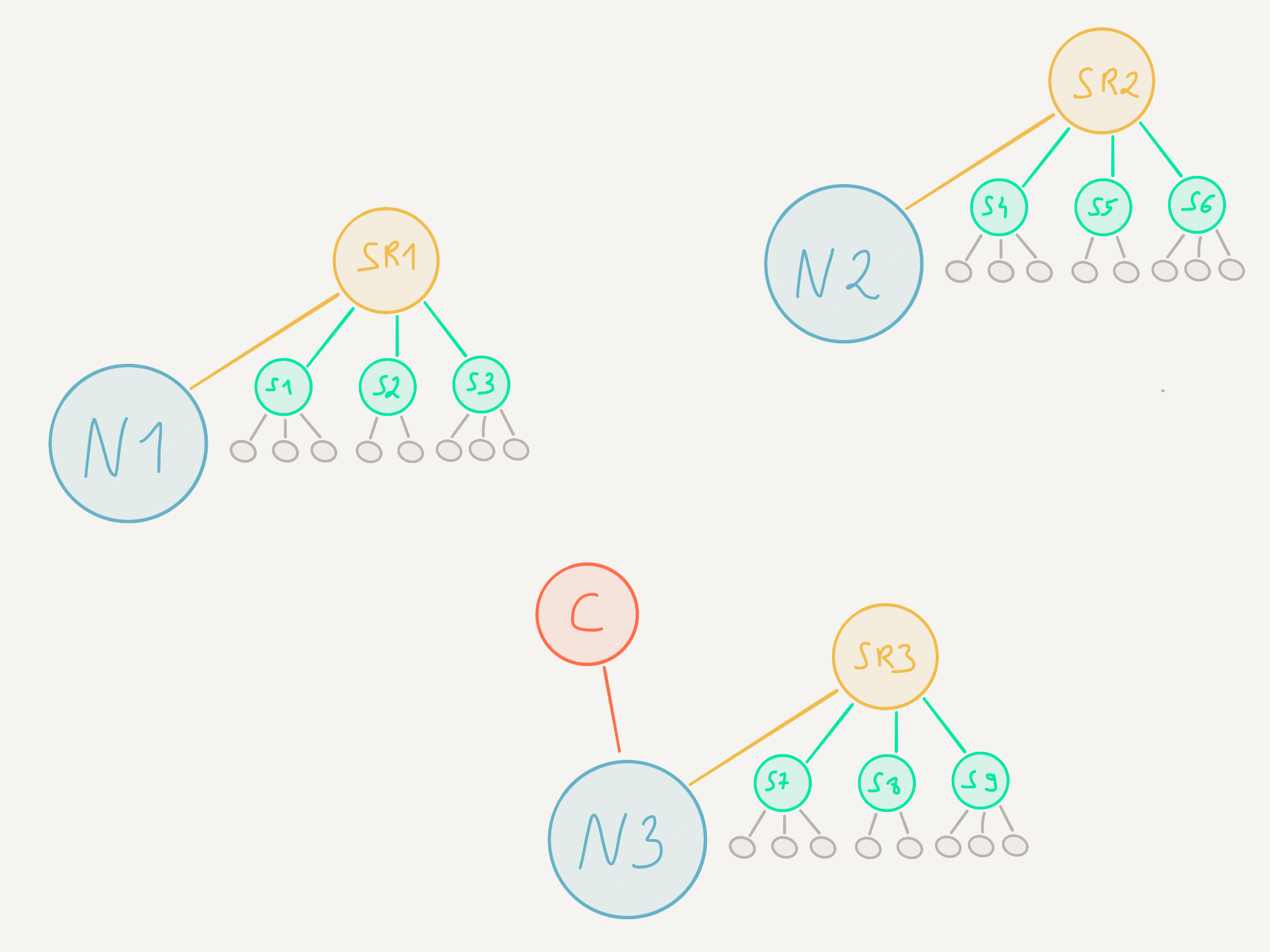
The code that we are writing - that is to say, the scale-agnostic code - is residing in entities. Entities are actors that are managed by Akka Cluster Sharding for us. There are three differences between entity actors and “standard” actors:
- messages should not be sent to the entity, but to the shard region actor of the sender’s node
- the lifecycle of those actors is handled by akka and not by us (we don’t create those actors directly)
- each entity needs to have an identifier that is globally unique. “Standard” actors may be given no name at all (managed by akka) or the same name in different parts of the hierarchy tree - in the case of cluster sharding entities, it is required for them to have a globally unique identifier.
The Akka Cluster Sharding machinery
On the scale-aware side of the architecture we can find shards, shard regions and one shard coordinator.
Shards are simply a group of entities. They are grouped together so as to be easier to move around (more on this later).
There is one shard region actor per node. These actors act as local proxy that gives access to the realm of sharded actors.
Some decisions need to be taken globally for the entire cluster and are executed by a cluster singleton actor (more on this later) called the shard coorindator. It is the shard coordinator that decides for example which shard gets to live in which shard region (which is to say, on which node).
Implementing cluster sharding for Merchant actors
Let’s go ahead and apply cluster sharding to a type of actor that will need have many different live instances active once our payment platform gets popular: the Merchant actor that we introduced previously. This actor is already durable thanks to Akka Persistence, which is something that matters quite a bit as we will see later.
In order to enable cluster sharding for an actor type, we need to provide akka with a few things:
- a way to retrieve the unique entity identifier from messages sent to entities. As you may recall, we no longer send messages directly to an entity actor but instead to the shard region of the sender’s node
- a way to compute a stable shard identifier from messages sent to entities
- the
Propsof the entity actor so that akka can create them for us - the sharing configuration
Starting cluster sharding on a node
In order to start cluster sharding on a node, we use the start method of the cluster sharding extension:
|
|
As you can see, this method call returns an ActorRef - this is the reference of the shard region actor running on the local node.
For this example, we will use the default ClusterShardingSettings but there are quite a few ways in which configuration can be tuned. Check out the reference documentation to learn more about these.
Let’s now have a look at how to implement extractEntityId and extractShardId, the two functions we need to implement in order to let akka figure out how to retrieve the unique entity identifier and stable shard identifier from messages the shard.
Extracting the entity identifier from messages
It turns out that in our case, since we made the Merchant actor persistent, every message sent to it implements the following trait:
|
|
This is quite useful now, because extracting the unique identifier of a merchant becomes trivial:
|
|
ShardRegion.ExtractEntityId is a type alias to a partial function that given a message, returns an EntityId (which in turn, is a type alias for String):
|
|
Extracting the shard identifier from messages
Entities are grouped in shards and therefore when we want to send a message to an entity, we need to know which shard it belongs to.
One of the most difficult design decisions to make when sharding data, be it with Akka Cluster Sharding or any other sharding technology (frequently a database) is to decide according to which criteria to distribute entities accross shards. The distribution should be uniform, i.e. you want to have about the same number of entities per shard, or else balancing load amongst nodes will become difficult.
The recommended rule of thumb is to have ten times as many shards as the maximum number of cluster nodes. If there are too few shards, some nodes would have nothing to do; conversely if there are too many shards then the load balancing mechanism (which we’ll discuss later) will be busy for no good reason.
A simple sharding algorithm uses the unique identifier of entities and is based on using a ring obtained from taking the absolute value of the hashcode of the identifier (remember that identifiers are stings):
|
|
In this example, we plan on having 10 cluster nodes at most, which is to say that we do not expect to ever need more than 10 cluster nodes to hold all our live Merchant entities.
ShardRegion.ExtractShardId is a type alias of a partial function that, given a message, computes a ShardRegion.ShardId (which happens to be a String):
|
|
This extraction function additionally also handles the ShardRegion.StartEntity message, which is a message that is used by the remember entities feature. This feature allows to automatically restart all the entities of a shard after a node crash or after rebalancing - without it, an entity actor, even if durable, is only called into life upon receiving a message.
Using the sharded entities in our system
Given that we do not have to change anything to the messages that we are sending to the Merchant actors, the only thing left to do is to adjust how we communicate with them in our system. In the previous article, we were just passing along a reference to a merchant actor (without routing involved), therefore we now can just replace this reference in the ReactivePaymentProcessor and pass it on to a Client:
|
|
That’s it! Our system is now ready to run with Akka Cluster Sharding in place. You can find the source code for this article here.
Akka Cluster Sharding under the hood
Now that we have looked at how to use cluster sharding in practice, an equally important part of designing and operating a system that makes use of Akka’s Cluster Sharding capabilities is to understand how some of its core mechanisms work in order to make the right decisions when it comes to evolving the system over time.
Message routing and buffering
When sending a message to a node’s ShardRegion we can be sure that it will eventually be routed to it. Note that this won’t magically ensure that the message will be delivered and processed - for at-least-once delivery semantics, please refer to the previous article of this series.
It is the shard coordinator that decides which shard is deployed on which node. As such, it is also the shard coordinator that can inform nodes as to where a shard lives:
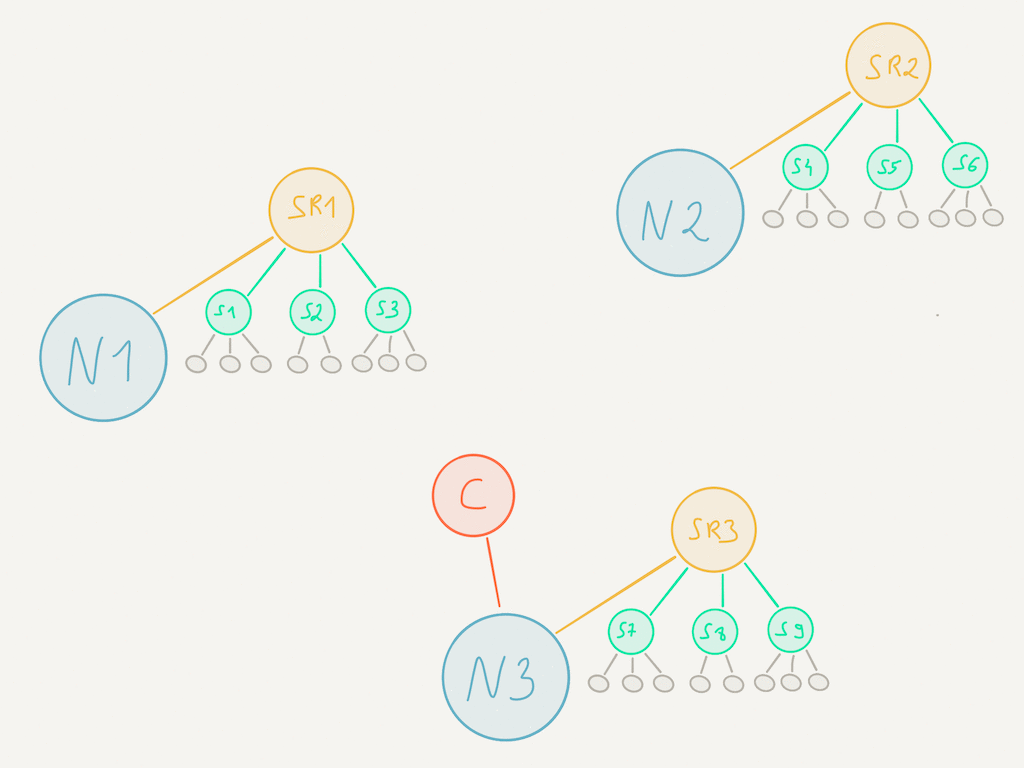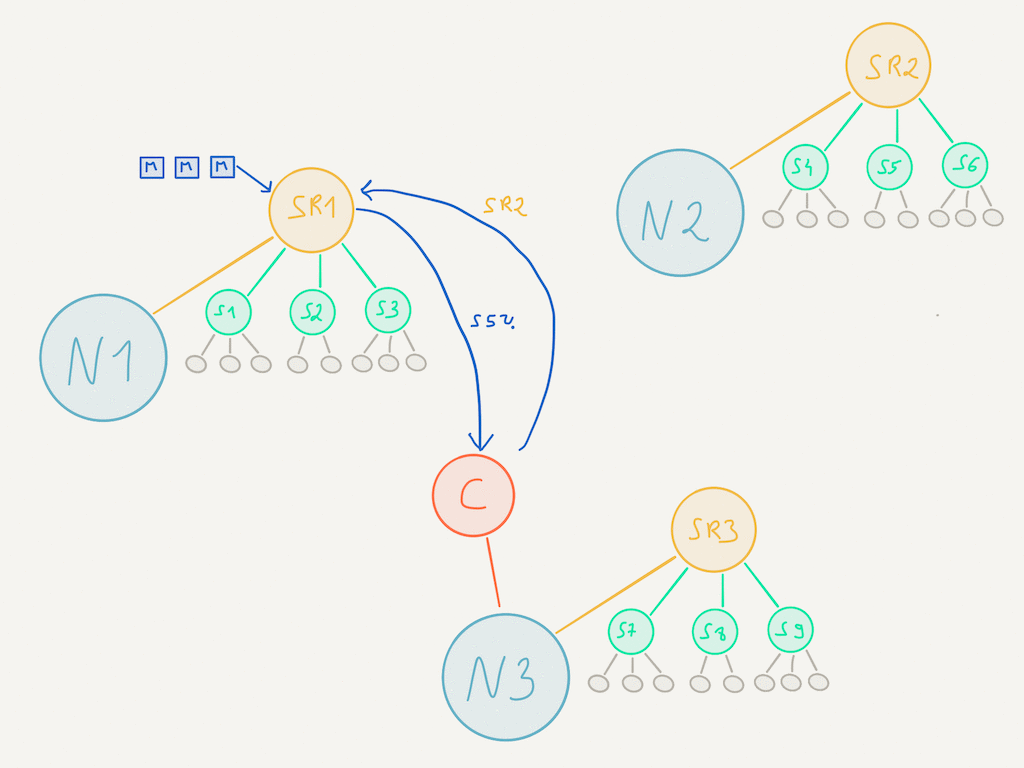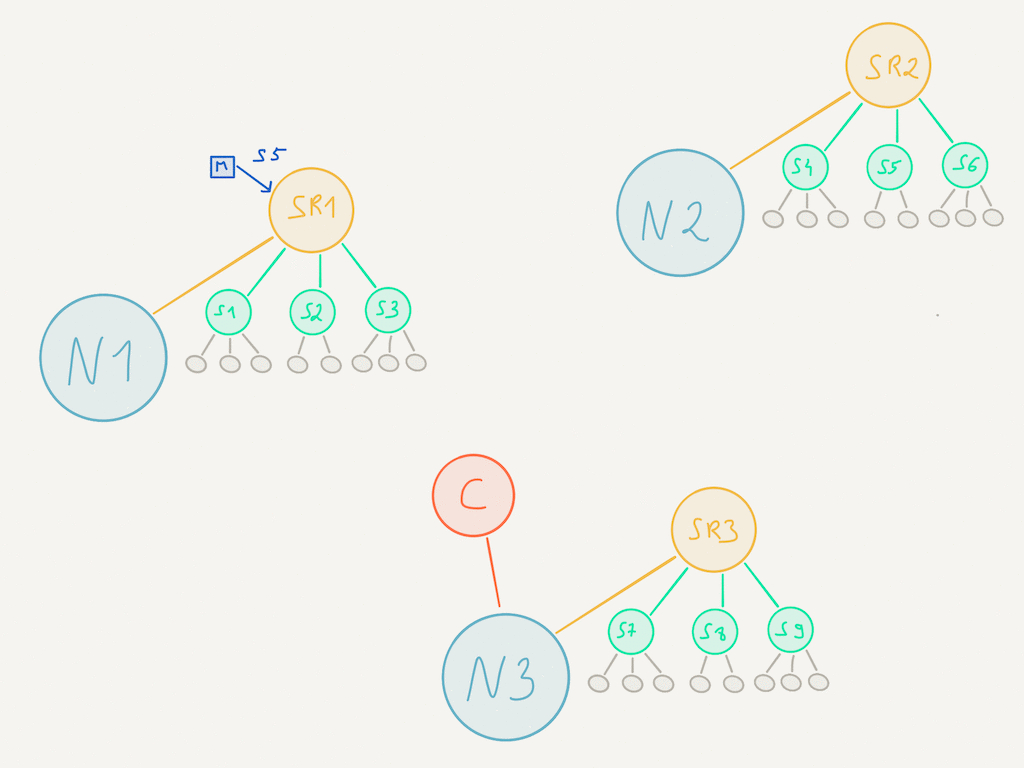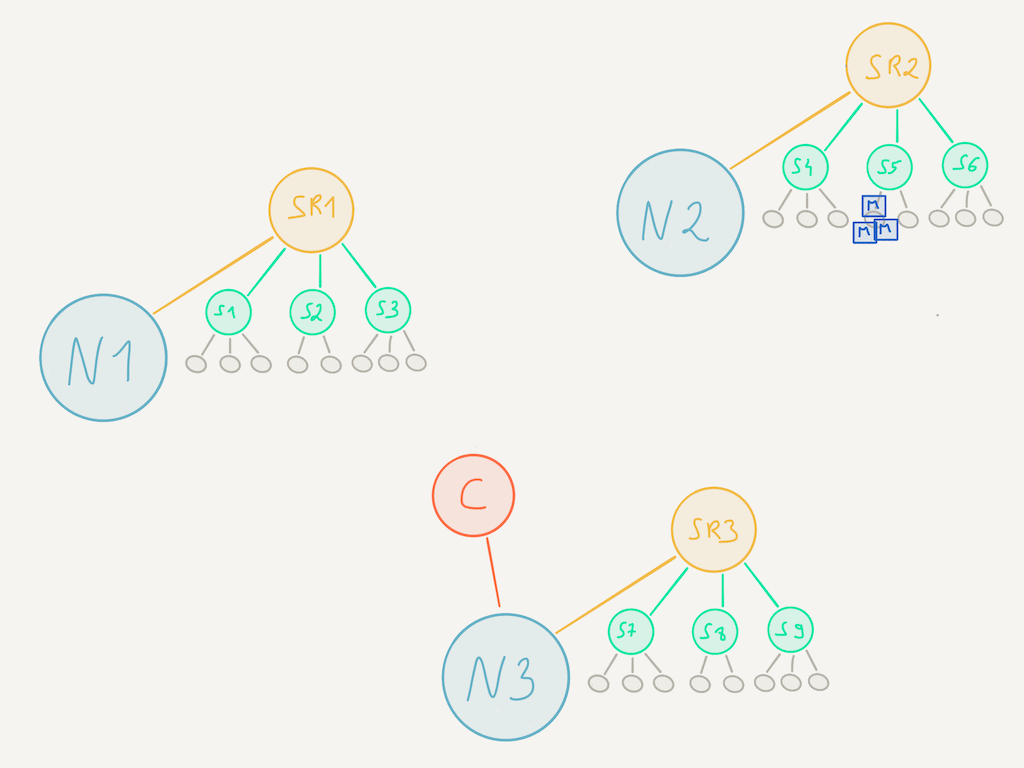
When a message is sent to a shard region, it will use the extractShardId method to figure out which shard this message should go to. If it does not know about the location of this shard, it will ask the coordinator about its whereabouts and use that response to route the messages accordingly. In subsequent requests, the location of the shard is known to the shard region (cached) so there’s no need to lookup its location at the coordinator.
While the routing mechanism is taking places, messages are buffered in a shard region and only delivered once the location is known.
Note that in order for this mechanism to survive the failure of the node hosting the shard coordinator, the state of the shard coordinator needs to be durable. This previously required to setup an Akka Persistence plugin for the Shard Coordinator - as of Akka 2.5 however, Akka Distributed Data (which we discussed previously is used for this purpose. The state that needs to survive crashes is the mapping between shards and shard region.
Rebalancing
When a node crashes or when the shard coordinator feels like it, shards are getting rebalanced, which is to say that they are being moved from one node to another. This mechanism is a key part of what makes Akka Cluster Sharding resilient and scalable and it is important to understand what happens with the entities during this process.
Let’s say for example that the shard coordinator is deciding to rebalance S9 to a new node N4 that just joined the cluster. This is what is going to happen:
- The shard coordinator informs all shard regions (SR1, SR2, SR3, SR4) that S9 is about to be rebalanced by sending them a
BeginHandoffmessage. As a result, the shard regions will start buffering messages adressed to this shard. During this process, the shard coordinator stops to respond to any location lookup requests. - The coordinator sends a
Handoffmessage to the shard region responsible for shard S9 - The shard region starts to stop all entities of the shard by sending them a configurable message which by default is
PoisonPill - When all entities are stopped, the shard region sends a
ShardStoppedmessage to the coordinator - The coordinator responds again to shard location requests which in turn bootstraps S9 at its new location
The default strategy for rebalancing shards is the LeastShardAllocationStrategy which, as its name indicates, will favour moving shards to the least busy region.
Passivation
Not all entity types need to be live in memory at all times. In our example, Merchant entities don’t need to be around all the time if they are not used: since these entities are durable, a message adressed to them will “wake them up” again from persistant storage at which point they will be loaded back in memory.
A graceful mechanism to achieve this is to send the Passivate message to the parent shard, which will be sent back when there are no messages left in queue for the entity to receive:
|
|
Conclusion
In this article we talked about Akka Cluster Sharding, a powerful feature that, combined with Akka Persistence, allows to scale out entities on several nodes so as to keep all state in memory. Routing messages to the entities and load balancing accross nodes is done transparently by Akka, leaving us with only a trivial amount of work to do when using this tool in our application.