Reactive Golf or Iteratees and all that stuff in practice, part 1
Contents
I’m currently working on a project that involves synchronizing large amounts of data from backend systems for the purpose of making it searchable. Amongst other things, one domain the system deals with is Golf and the booking of tee times (i.e. a time at which to start playing). If I got things correctly, tee times are there in order to avoid getting hit by a player that starts later on (I haven’t played golf yet).
The portal is written on top of the Play! Framework and the search engine in use is ElasticSearch.
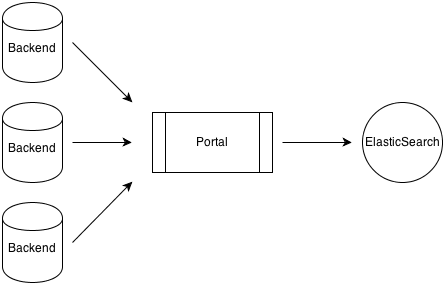
There are two cases of data synchronization:
- a full synchronization run, when initially connecting a new tenant or regularly at night to make sure both systems really are in sync, as pull from the portal
- when a single tee time is modified (e.g. when it gets booked), as push from the backend systems
The case we’re going to explore more into depth is the full synchronization, as this is the case that will need to scale up as the number of tenants and the variety of data to synchronize will grow.
Both the backend and ElasticSearch use JSON to encode the data, and the portal has to do some enhancements to turn the raw tee time into a document suitable for indexing.
Fetching the data
In order to fetch the data from a tenant, we’re using Play’s play.api.libs.WS library, like so:
| |
The infinite request timeout is there because we may potentially get a fair amount of data, which in turn may take quite a while to reach us all.
Reactive streaming
The idea behind “reactive” streaming is that we only use resources (CPU, memory, etc.) when there’s a reason for it, i.e. when there’s data. Instead of retrieving all of the data in memory and then sending it off to ElasticSearch, our portal should be able to pass it on directly to ElasticSearch. Otherwise, it may require quite a bit of memory to handle streams that come in at the same time.
The tooling that the Play framework offers for this purpose are the so-called Iteratees, Enumerators and Enumeratees. There’s an excellent introduction by Pascal Voitot on the topic, I hope that this practical example can help to give a bit more background as to how this tooling can be used.
Basic piping: connecting input and output
So on one hand, we are doing a WS call to retrieve our data, and on the other hand, we’d like to send it out after being modified a bit. Play 2.2 offers the Concurrent.joined[A] method to do just that. There are 3 things that are good to know prior to looking into this method:
- an iteratee is the data consumer, i.e. the “pipe” into which data will flow
- an enumerator is the data producer, i.e. where the data flows from
- these streams always deal with a certain type of data. In our case, the type of data is going to be an array of bytes, since we get raw data over the web from a call to a REST API.
The scaladoc of the Concurrent.joined[A] method says:
| |
So, we need to apply the iteratee in the pair to something (for the “pipe” to get some “water”), and subsequently we can run the whole machinery by applying the enumerator to it. Let’s see how that would look like on the one end with our previous WS call:
| |
This may look a bit spooky, but it’s quite simple. The get method performs a get request which takes a consumer, and which then eventually will return a connected iteratee. From the scaladoc:
| |
With the flatMap statement, we’re taking whatever is inside of that Future “box” and run it, and then unwrap the result of the run (which is itself a future, because that’s what the run function returns).
Ok, now, we have some water coming in on one end of the pipe. Let’s see what to do with it.
Enumeratees or how to transform streams on the fly
An enumerator is a data producer, and an enumeratee is a nifty tool that lets us work on a reactive data stream on the fly. We can compose our enumeratee with an enumerator, like so:
| |
Ok, that’s quite a bit of enumeratees there at once. Let’s look into this in detail:
- the &> sign just means “compose”, i.e. chain things together
- the first
mapenumeratee will take the input (which is of typeArray[Byte]) and parse it as JSON - the second
mapenumeratee will take the resultingJsValue-s from the previous enumeratee and read them into something with theformat.readsfunction - the third enumeratee collects all values of a certain kind, i.e. acts as a filter. It gets as input a
JsResult[TeeTime], which may either beJsSuccessorJsError(this is part of the standard Play JSON library) - finally, the last enumeratee will pick out the
TeeTime-s returned by the previous step and put them into aGolfIndexDocumentready to be sent off to ElasticSearch
This is all pretty great. There’s just one gotcha: the pipe-line above assumes that we’ll always be able to turn our first chunk of Array[Byte] into a JsValue, i.e. that it is a complete JSON token, which doesn’t get cut in the middle (e.g. {"foo": "ba and then r"}). That actually may hold true for not too large objects. However, it would also mean that we’d expect to get a stream of serialized JSON objects from our backend. But that’s not the case… we get a JSON array containing all of those objects.
So at this point, we would need an enumeratee that is capable of dealing with incomplete chunks of JSON, and reassemble them, reactively, taking into account all kind of edge cases… which all sounds pretty complex. Luckily for us, the universe created James Roper, and James Roper created the JSON iteratees and enumeratees.
So armed with this new tool, let’s rewrite our pipe-line:
| |
Now that’s pretty cool, isn’t it? There’s just one last catch: the enumerator provides data of type Array[Byte] and the JsonEnumeratees.jsArray enumeratee expects data of type… Array[Char].
We could fix this by being rather blunt and inserting the following enumeratee:
| |
However, that would then only work for ASCII encoding, and we likely will get something a bit richer, such as UTF-8. Luckily enough, James also wrote a tool for this, so our complete chain now looks as follows:
| |
Voilà, we now have a pipe-line that turns a raw array of bytes into full-fledged GolfIndexDocument-s ready to be sent off to ElasticSearch!
We’ll see how to do this in part 2, so stay tuned!