Reactive Golf or Iteratees and all that stuff in practice, part 3
Contents
In part 1 and 2 we’ve seen how to build a completely reactive chain to fetch a large stream of data from a REST API, transform it on the fly and send it over to indexing to ElasticSearch.
Now one question remains: does it actually work, and does it help solve a real problem?
In order to answer to this question, let’s build a naive, blocking version of the pipe-line above. We’ll consume the stream, then transform it, and then send it over to ElasticSearch, in chunks:
| |
As you can see, the code above is really quite naive. The response of the WS call is being consumed in its entirety, then parsed into a (long, long) List[TeeTime], turned into a list of GolfIndexDocument-s and then sent over to ElasticSearch in chunks of 100.
Let’s now see how things go when running the reactive vs. the “naive blocking” solution, with YourKit.
We start with the reactive solution, without very much memory consumption:
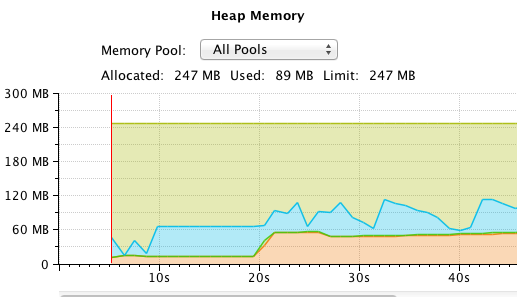
The memory consumption then increases, steadily, in longer spikes of objects living in the eden space:
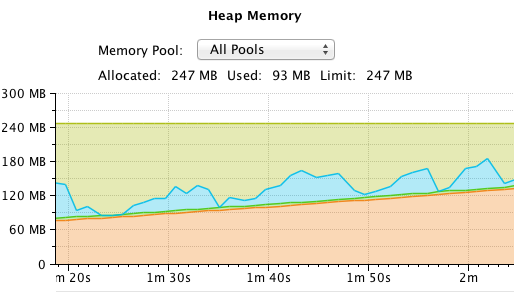
During that time, the minor GC looks like this:
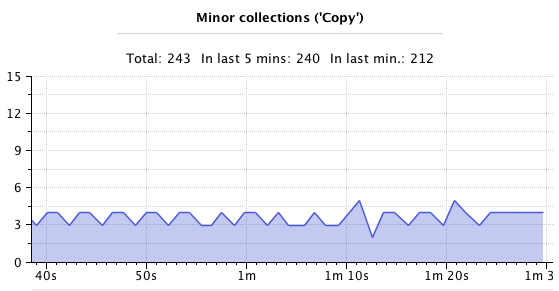
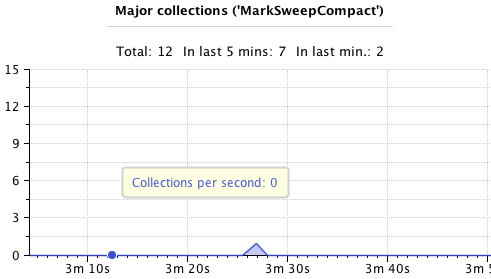
Until finally we need a major collection to free up memory:
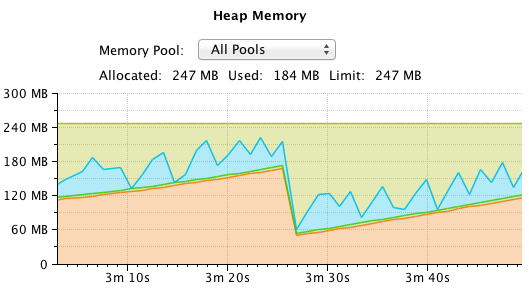
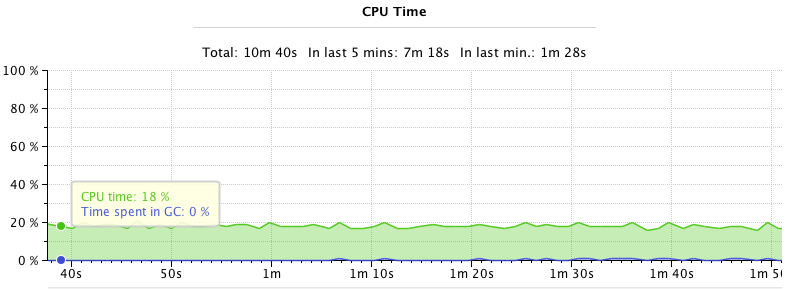
CPU usage is not very high:
And we’re progressing nicely, albeit slowly:
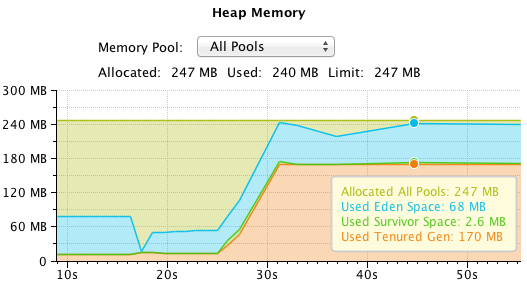
Now, let’s try things with the blocking approach. We start off with a rather high memory consumption:
And don’t really get much further, because we eventually run out of memory which causes JSON parsing to deadlock:
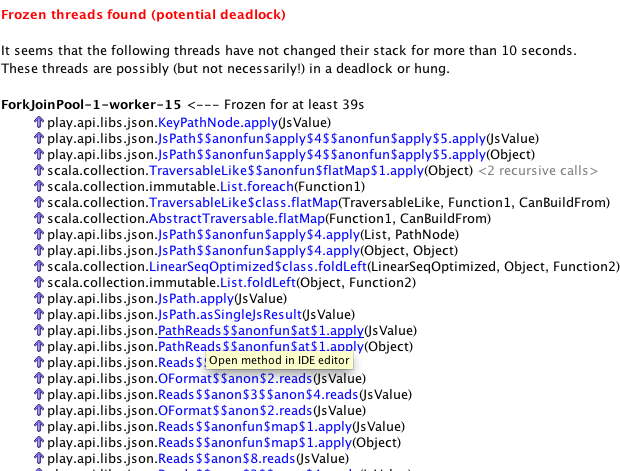
Conclusion & thoughts
Working with reactive streams is getting increasingly easier as the tooling gets better. I found that the Iteratee, Enumerator and Enumeratee APIs as well as all the tooling in play.api.libs.iteratee.Concurrent is really getting to a point where it can easily be used, and where one doesn’t necessarily need to concern themselves with all the underlying details as to how Iteratees are implemented (even though I find it useful to understand how things work, to some degree).
For the use-case at hand, another obvious solution is to implement a smarter “blocking” solution by retrieving the data in smaller chunks, rather than all at once. Yet this approach also brings its disadvantages and requires a more sophisticated synchronisation mechanism (how much have we retrieved last time, what to do in case a chunk gets lost, etc.). Or to run the server with a sizeable amount of memory - though that approach will eventually stop working as the amount of backend systems to synchronise from grows. The drawback of using the iteratee tooling in this case is that it is much slower than the blocking approach, which has a much faster JSON parser (given enough memory, the blocking implementation eventually starts working, and is then much faster).
I think the most suited use-case for the reactive streaming are situations where one has to deal with “infinite” streams, i.e. streams may or may not produce data. In this case the non-blocking, resource-friendly nature of reactive streams really shine, in comparison to their blocking counterpart that will keep a few threads busy while waiting indefinitely for data to come in.
All in all it was fun, and I am looking forward to using this tooling more often in the future!