A new adaptive accrual failure detector for Akka
Contents
Akka uses the The Φ Accrual Failure Detector for failure detection, which is to say for answering the question of whether a node is alive or not. That’s one of the harder problems of distributed systems since it is virtually impossible (from the point of view of one node) to tell the difference of a remote system being completely unavailable (process crashed, computer died, etc.) or slow (network congestion, other kind of congestion such as CPU during a garbage collection for JVM processes, etc.).
Now, the Φ Accrual Failure Detector has certainly a nice name to it. Phi. Just casually mentioning it in a conversation makes you sound a lot smarter (at least if you’re hanging out with people inclined to software engineering - in other social circumstances, it doesn’t work that well). And believe it or not, phi is also the metric by which to measure consciousness. So why look for something else? Well, the original paper is from 2004 and so I started wondering whether there hasn’t been, in all of those years, any new research related to failure detectors. As a result of searching a bit I found quite a few interesting papers. Since I’ve gotten the hang of the slight sense of desperation and feeling of inexorable existential crisis that comes with working with distributed systems I decided to go ahead and test out a few of those new approaches to failure detection.
This article covers my findings and learnings during the implementation and benchmarking of a new accrual failure detector.
A New Adaptive Accrual Failure Detector for Dependable Distributed Systems
In this paper Satzger et al. describe a failure detector based on approximating the cumulative distribution function (CDF) of heartbeat inter-arrival times which is significantly easier to compute than φ. Both the Φ failure detector and this new adaptive failure detector are so-called accrual failure detectors, which is to say that they keep a history of past heartbeat inter-arrival times. Without wanting to go in the detail of the paper one of the advantages of the adaptive accrual failure detector over the Φ accrual failure detector is that the former does not assume normal distributed inter-arrival times which can be quite useful in varying network conditions.
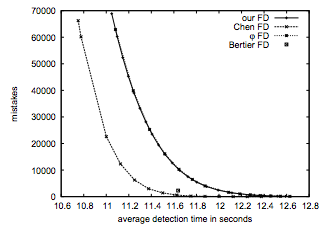
Given the similar nature of those failure detectors and since the paper claimed that this new failure detector was outperforming Φ (see the graph above) I decided to go with implementing it as a candidate for this experiment and see if I could reproduce the paper’s claims in practice. Given that they are both based on process monitoring using heartbeat reponses this also meant that I could simply switch out the Φ accrual failure detector without touching any other part of Akka, which may be required for other types of failure detectors out there.
The benchmark process
I wanted to be able to benchmark different failure detector implementations with varying parameters and for various cluster sizes (3, 10, 50, 100, 400). For this I needed a way to create the infrastructure and then a way to run and report benchmarking results.
For example, I wanted to be able to run 6 scenarios (on the same machines) with varying parameters:
| |
A pseudo-algorithm of a complete benchmark session for N nodes looks as follows:
for each scenario
for N rounds
wait for M member nodes to have joined
select one member at random
inform all members that this node is expected to become unreachable
instruct the member to become unreachable
collect the unreachability detection time of each member
instruct everyone to restart their actor system with the settings for the next step
An email report is generated after each round and the complete set of detection times is sent out when the entire benchmark is done.
The benchmark rig
Building the infrastructure with Terraform
In order to build the testing infrastructure I used Terraform on AWS. The terraform configuration first creates a standard Ubuntu node, then provisions it with the JVM, a Consul client and the Akka JAR and turns this instance into an AMI. This image is then used to create N instances in a much faster fashion than provisioning each instance from the start. Terraform also creates other necessary resources such as the AWS placement group. The Consul cluster (3 nodes) is also created using Terraform.
Assembling the cluster with ConstructR
In order for nodes to find eachother without necessarily knowing which IP addresses they will have, I used Heiko Seeberger’s ConstructR together with the Consul module. This really worked well, including for large clusters (the only thing to take care of for those was to slightly increase coordination timeouts, join timeouts and number of retries).
Logging with Papertrail
I used Papertrail in order to get a sense of what is happening on the nodes. There’s no need to register systems with Papertrail, they get dynamically added which is very convenient for such an experiment with dynamic infrastructure. The logs are easy to filter and to search, which makes it easier to look for failure causes.
I setup Papertrail using logback and logback-syslog4j, all the instructions for this are provided by Papertrail so it is quite an easy setup.
Reporting with Mailgun
There’s probably plenty of alternatives for this but I thought I would mention it anyway: Mailgun has a very nice API for sending e-mails. I used the standalone Play WS library for making calls to it.
Benchmarking with Akka FSM
The benchmark is performed by a cluster singleton actor (the benchmark coordinator) that is also an FSM actor. The states are:
WaitingForMembersPreparingBenchmarkBenchmarkingDone
During a benchmarking round the happy path will be WaitingForMembers -> PreparingBenchmark -> Benchmarking -> WaitingForMembers -> etc. until the round is done. Then the coordinator asks all members to reconfigure themselves and this goes on until all steps are through. As we’ll see later though, the larger the cluster, the lower the chances are that the happy path will be followed as such and instead the chance of temporarily “loosing” a member increases as the cluster size increases.
Benchmark runs and results
The sweet spot for the phi accrual failure detector according to the paper is for 8 <= Φ < 12, where 12 has a lower mistake rate but a higher detection time. Further, the experimental results presented in the paper “[show] a sharp increase in the average detection time for threshold values beyond 10 or 11”.
For the adaptive accrual failure detector, there is no optimal range given but the meaning of the threshold is more intuitive as it represents the maximum failure probability, e.g. a threshold of 0.05 means that there is a probability of 0.95 that the remote system has failed. Furher, the adaptive failure detector has another tuning parameter, the scaling factor Α that “is used to prevent the failure detector to overestimate the probability of failures particularly in the case of increasing network latency times”. In this experiment Φ is set to 0.9.
Taking this into account I’ve run the benchmark for Φ = 8, Φ = 9, Φ = 10 and for p = 0.2, p = 0.25, p = 0.3 as well as p = 0.05 (out of curiosity). Note that when using the phi accrual failure detector in combination with cloud-based deployments you shouldn’t rely on values of the thresholds that are too tight (i.e. that can be influenced by lost heartbeat messages) since the likelyhood of having network trouble on this type of infrastructure is higher than when running it on a plain LAN (more on this later) and this can trip the phi failure-detector which relies on normal distributed inter-arrival times.
Without further ado, here are some summarized results:
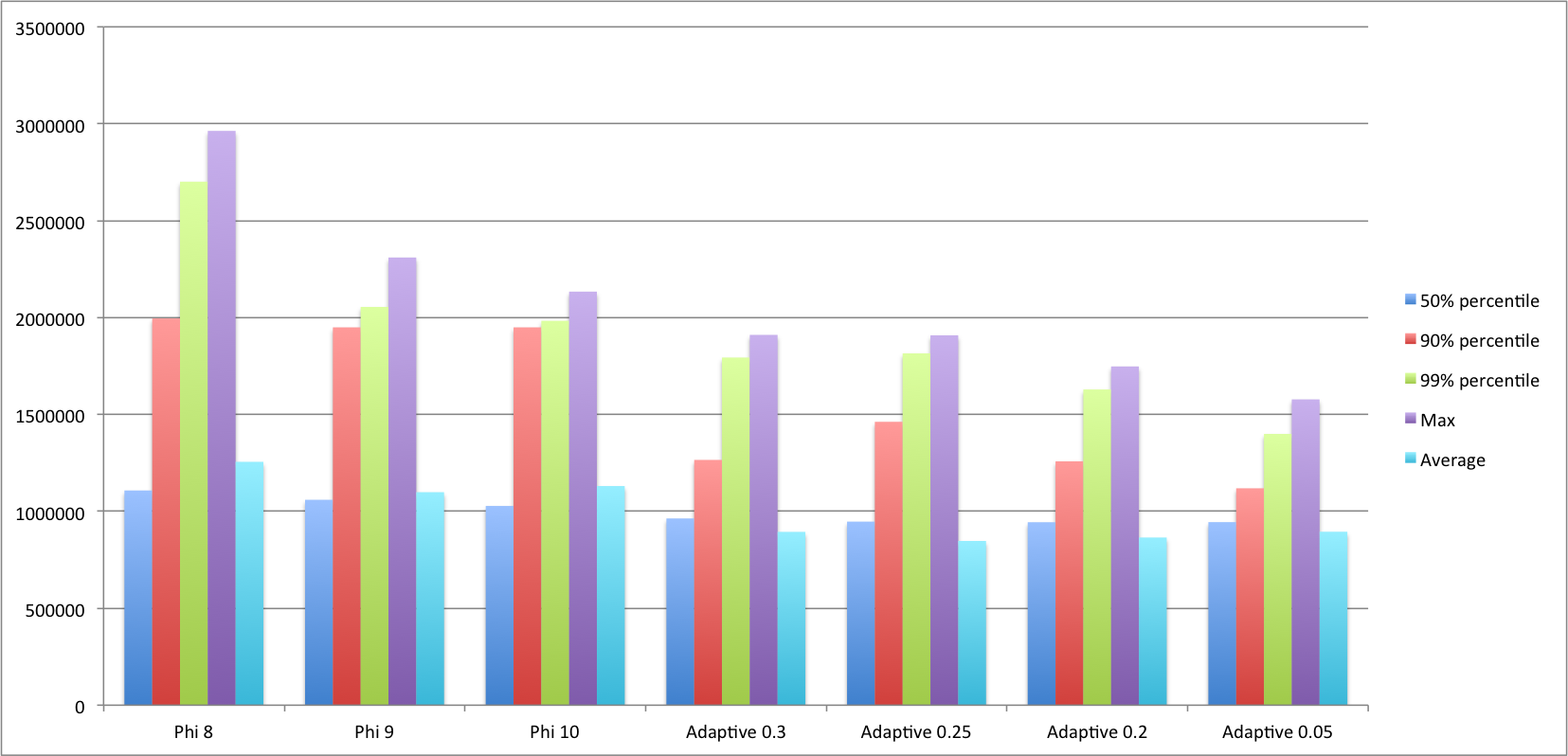
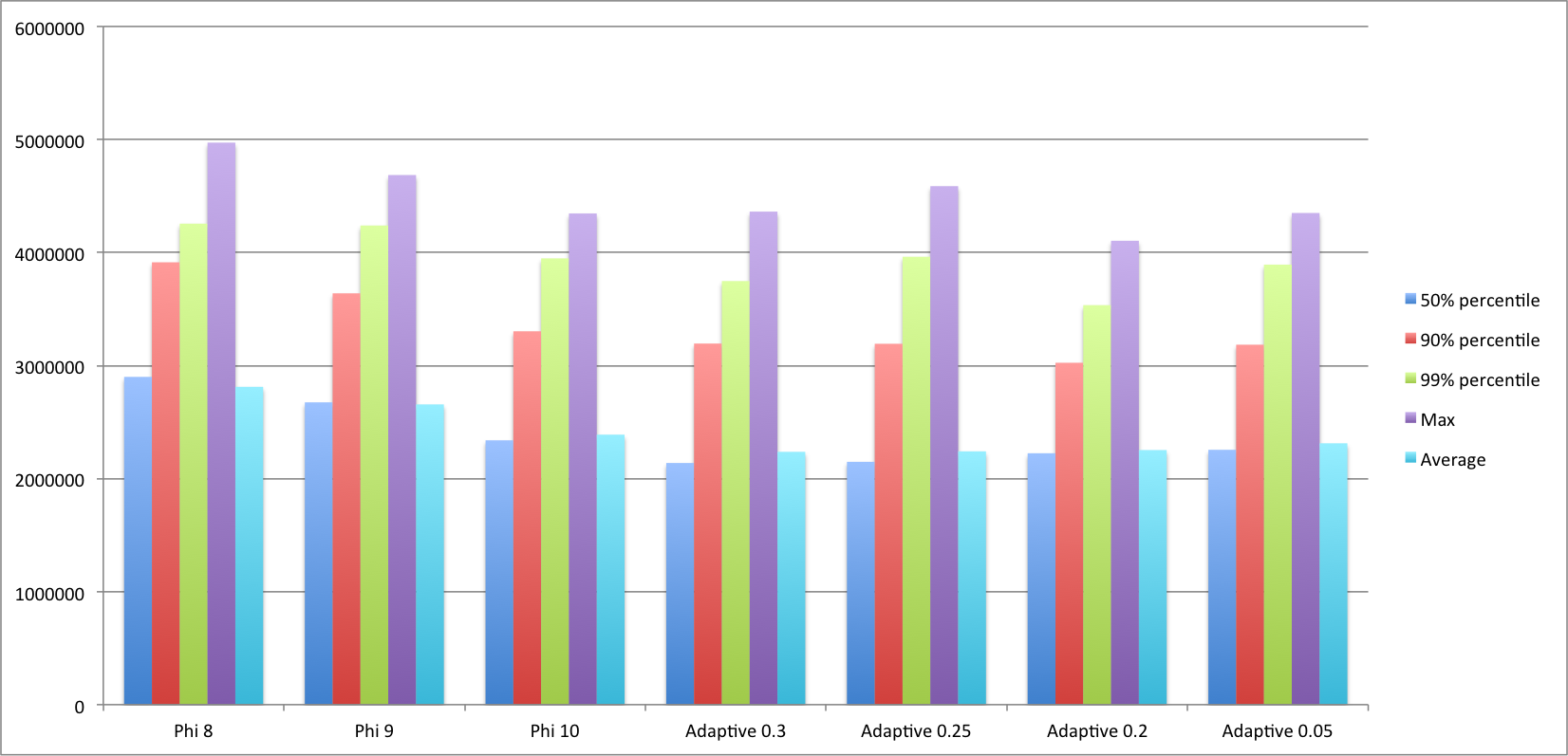
What’s also interesting to look at is the detailed frequency distribution histograms for both types of failure detectors:
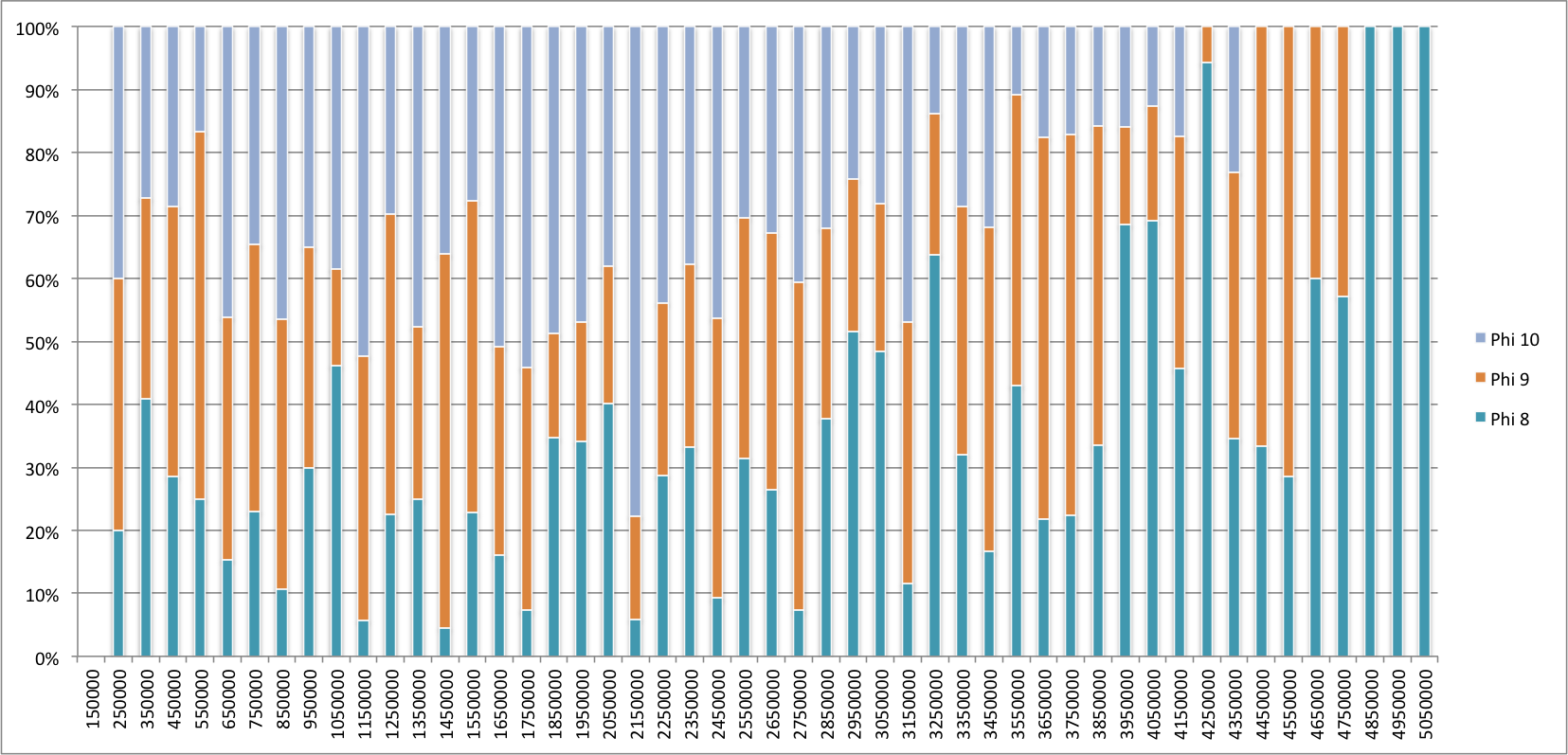
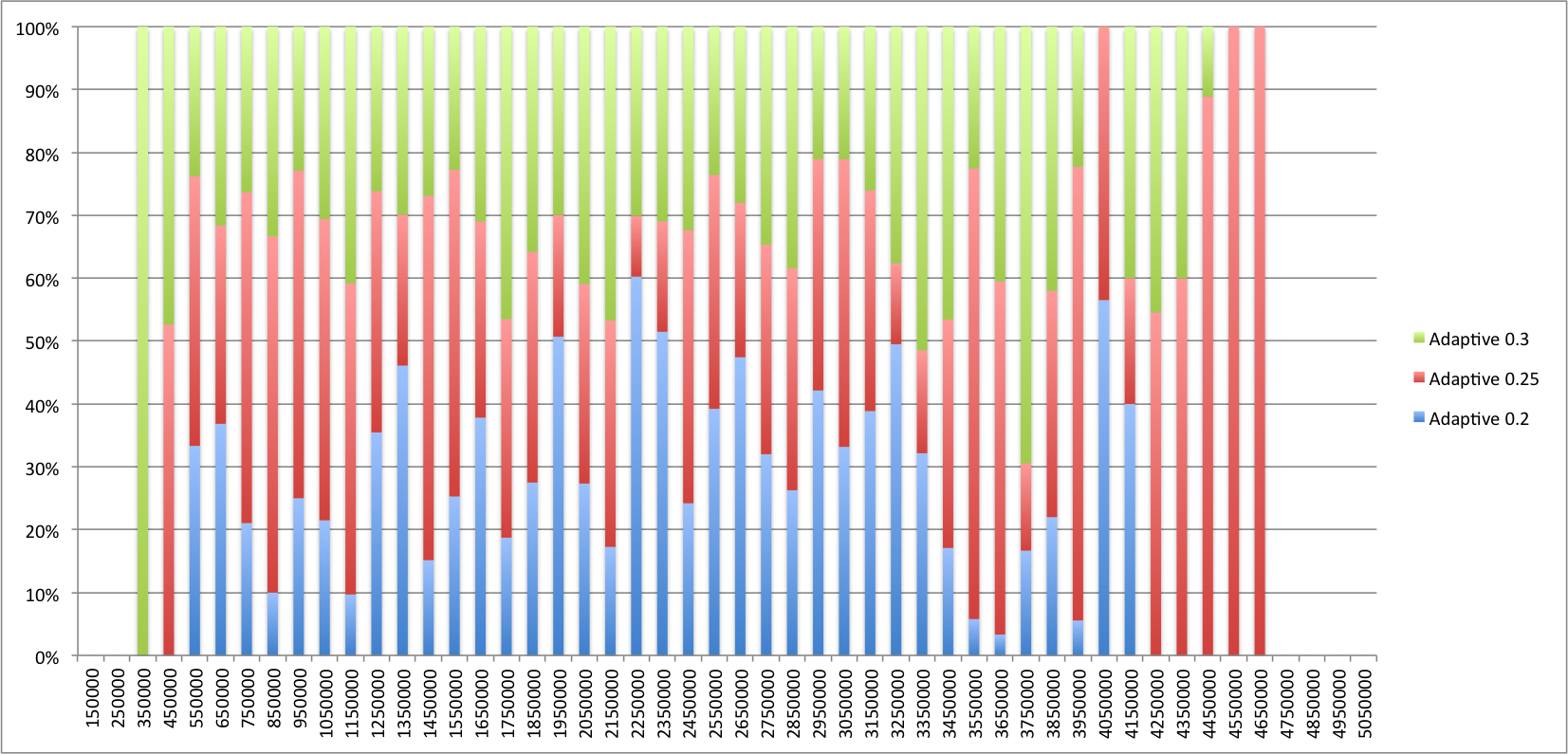
So what does it all mean?
For the threshold values of Φ and p for which we’ve ran the experiment the adaptive failure detector seems to perform slightly better than the Φ failure detector. What’s perhaps more interesting, at least to me, rather than comparing performance is that it works. What I mean to say is that in practice the adaptive failure detector is a viable alternative to Φ which is much simpler to implement and offers, in my opinion, two significant advantages over the Φ accrual failure detector:
- the threshold is expressed in terms of failure probability rather than in terms of Φ which - as cool as it sounds - isn’t a very intuitive value to grasp
- the adaptive failure detector, as its name indicates, is capable of adjusting to changing network conditions. If the network for one reason or another has varying conditions resulting in changing heartbeat inter-arrival times then this failure detector will still be able to deal with it. I think that this can be particularly interesting when using Akka in cloud environments with a low QoS (e.g. in the AWS example without placement groups).
Observations, learnings and other comments
More interesting than the results in themselves has been to me what I’ve learned while building the benchmark setup.
Large clusters
When you start operating at a certain scale the system doesn’t obey the same laws it does in a smaller variant. You don’t merely see a set of problems that arise at a small scale as being amplified, instead, there is a whole new set of issues arising at a large scale that did not affect you beforehand.
Getting the benchmark to run for up to 100 nodes took about 20% of the time I spent on the experiment, the remaining 80% of the time I spent on getting it to work reliably for 400 nodes. And in order to get it to work I had to:
- switch from t2.micro instances to c4.large as these allowed the use of placement groups - without them the instances would be spread around too much in the AWS zone and the cluster simply wouldn’t converge anymore with the phi failure detector which made it impossible to move forward
- create a system with a new name at each benchmark step. Whilst at smaller sizes all nodes would shut down and join the system again fast enough, with 400 nodes it would take too long for the shutdown to take effect, resulting in the co-existence of nodes in the old and new configurations (i.e. some members with one failure detector or threshold and some nodes with another failure detector or threshold)
- introduce a split brain resolver since at this scale there were enough occurrences of such events to observe and hinder the run (more on this later)
- introduce state timeouts for benchmarking and benchmark preparation states to reset a stuck round
- change the deployment scheme from directly provisioning each node via terraform to first creating a template and then an AMI out of the template as provisioning would otherwise take too long (this one is arguably a minor inconvenience but is nonetheless a practical burden when operating at scale and a good example demonstrating the usefulness of all the new operations automation tools that have come into existence in the few past years)
Cluster stability
Since we’re using Akka as a tool to benchmark the Akka failure detector, the benchmark itself is affected by errors in the failure detection and generally by the challenge of having a stable cluster.
Surviving false positives
In the experiment we only really expect one node to become unreachable at each round - the one that we’ve explicitly asked to go away. If any other node becomes unavailable then one of two things has happened: either the failure detector has erred (more likely) or the node really become unreachable due to a network partition or sudden increase in inter-arrival times (less likely, but as we’ll see, not impossible). It was therefore important to devise a process by which we can discard those scenarios. In practice each unscheduled unreachability notification received by the coordinator would trigger a 5 second timer that would eventually instruct the suspected node to restart. If no reachability notification is received within 5 seconds this node would then restart and eventually become a proper member of the cluster again.
Surviving network partitions
I already knew that the AWS cloud was subject to occasional network partitions and this experiment showed me how frequently this appears to happen. It didn’t really matter if I ended up paying 600 $ to get access to instances living in the same placement group, I still got a fair number of network partitions even within the same placement group. Granted, the partitions didn’t last very long but long enough to trip my experiment, which was annoying.
Interestingly those occurrences were mostly limited to single nodes which were still able to communicate with the outside world and send logs out. Not that that’s a good thing though, this is actually your worst case scenario (having parts of the system not being to talk with one another, but be able to accept requests from the outside).
I ended up implementing a primitive split brain resolver for this experiment just to be able to perform an entire run without hiccups.
Cluster convergence
While developing the experiment I often had to think of the video above. This is what the cluster felt like at a large scale. See, each round would only be truly done if there had not been anything unexpected happening during the round: no unscheduled unreachable member, no removed member, no lost / unacknowledged messages, etc. In order to guarantee this it turns out that the best survival strategy is the simplest one - to reset the round and go back into the WaitingForMembers state, waiting for the cluster to stabilize and all members to be available.
It’s easy to see how large clusters become a very hard thing to achieve. The Akka Cluster is a membership service, providing the platform for building a distributed system running on member nodes. The larger the cluster gets the harder it is to reach a stable size for all members. Not all applications may need this - especially when the aim is to distribute computational load then cluster convergence is maybe not that important, something that is reflected in Akka 2.5 promoting the WeaklyUp member state to be on by default. In this experiment however where cluster stability is required to have a baseline to work with, even at only 400 members the difficulty starts to show.
Misc
- in this experiment the JVM is always on between consecutive steps. Reconfiguration hence means that the actor system needs to be shut down and brought back with a new configuration. At the same time it needs to be able to recover from being shut down in case of unexpected failure - for example, the ConstructR shuts the system down if it can’t talk with the coordination service which happened in some rare cases. Being able to tell the difference between these scenarios and recover from them in each case was an interesting exercise
- since part of the experiment was to run a benchmark, it was important to eliminate some aspects that would skew the benchmark. For one, there’s a warmup time at the beginning of each step so that the failure detector gets a baseline of heartbeat inter-arrival times. Secondly there’s one “blank round” in each benchmark at the beginning just to warm the JVMs up.
- messages are sent using at-least-once delivery semantics (handcrafted, using the ask and pipe patterns) because - surprise - without this, a few of them would get lost
- in an early version of the benchmark the detection timing was based on timestamps rather than durations. I very quickly came to see that NTP will not cut it in this case and that each node had to measure the duration on its own. It’s interesting how often I still fall into this trap.
TODO / open loops
- there could be another experiment that would slowly degrade the network (but how?) and show how both FDs behave in this case
- the benchmark isn’t meant to measure absolute values but rather the re
- is there any way to reasonably test the benchmark tool itself? Does that even make sense? I mean, how do you write an integration test simulating 400 nodes and a network that sometimes fails? That doesn’t seem very practical.
- clean up the code, sort it out and make it available. Our second kid was born 2 weeks ago and so this may take a while. But you can already have a look at the code for the terraform cluster configuration
That’s it for this experiment. If you have questions or comments please let me know. I’m also available on Twitter. If you are using Akka Cluster or are thinking about using it and would like some help, we can work on it together.