Tour of Akka Typed: supervision and signals
Contents
Update 18.10.2019: fixed wrong syntax for handling multiple exceptions, clarifying a few points
Welcome to the third part of the Akka Typed series. In the first part we had a look at the the raison d’être of Akka Typed and what advantages it has over the classic, untyped API. In the second part we introduced the concepts of message adapters, the ask pattern and actor discovery. In this part of the series, we’ll have a look at one of the core concepts of actor systems: supervision and failure recovery.
Supervision
In the actor model, there’s an important distinction between business logic errors that are expected as part of the flow of the application and system-level failures that may happen for unexpected reasons such as a third-party system not being available. In the latter case, trying to deal with the failure inside of the affected actor may not be very practical since the cause is outside of its area of control. Instead, it may be more adequate to let the failure be dealt with by a mechanism that exists outside of the affected actor. This failure handling mechanism is called supervision and Akka provides a few ways in which this mechanism can be applied.
The supervision mechanism in the Akka Typed API is quite different from the one in the classic API for very good reasons which I won’t repeat here (but if you haven’t check out the linked article, it’s a short read and provides the necessary background information). Supervision is no longer bound to the hierarchical relationship between actors. Instead, behaviors can be wrapped inside of a supervision decorator that allow to specify what happens when the actor fails. The supervisor is still declared “outside” of the actor, but on the implementation side of things, parent actors no longer need to know all the details necessary to handle the supervision of their children.
There’s another important difference between the Akka Typed API and the classic one: when an actor fails, it is now stopped by default rather than restarted. In my experience I’ve seen many newcomers to Akka be puzzling for quite a while as to why their actor system wasn’t working as expected all the whilst not seeing any noticing the exception in the logs, when what was happening was that an actor was restarting in a loop (misconfiguring the logging framework can cause you not to see any logs from akka loggers you need to have lifecycle logging enabled in debug mode to see this, which it is not by default). When a crashing actor is stopped rather than restarted it usually becomes quite visible that something odd is happening. So I think that this default behavior will make it easier for developers to get started with Akka in the future.
Note that when we talk about failures in the context of an Akka actor, what this translates to in terms of implementation are Throwable-s: any NonFatal Throwable raised inside of an actor leads to its failure and to the supervision mechanism to kick in.
Declaring supervision strategies
In order to specify how failure within one behavior should be handled, there’s a supervise wrapper:
| |
With this supervision in place, if a StorageFailedException is thrown during the execution of the process behavior, the behavior will be restarted and any state it might carry be lost. Note that in this case (assuming there’s no nested behaviors) there isn’t any state here as process doesn’t take any parameters.
It is possible to handle different types of exceptions by nesting multiple supervise calls:
| |
The possible decisions as to what to do with a failing actor are to:
- stop it
- restart it
- restart it with a delay (exponential backoff, very convenient when it comes to interacting with third-party systems that may be temporarily overwhelmed or need time to restart after a failure)
- resume the execution (and ignore the message that caused failure)
If you’re familiar with the classic Akka actor API, you’re probably wondering what happened to escalating failures — we’ll look into this later.
Supervising child actors
Let’s go back to the PaymentProcessor actor of the first article which was bootstrapping the actor hierarchy:
| |
If we want to, we can add custom supervision to individual child actors here, for example for the CreditCardProcessor which may be subject to having its storage service become unavailable:
| |
Note that we use the restartWithBackoff strategy here in order not to stress the failed storage system and give it a chance to get back on its feet. In the classic Akka actor API, this could be achieved using a BackoffSupervisor with the drawback of it introducing a dedicated actor — with Akka Typed, this is now part of the standard supervision mechnism design.
Let’s now have a look at supervising our guardian actor. By default it would be stopped in case of a crash by Akka alongside the entire actor system, let us change this to have it be restarted instead:
| |
When supervising child actors this way, they will be stopped when the parent actor is restarted. In other words, if our behavior fails for one reason or another, the existing config and creditCardProcessor actors will be stopped as well (and created again when / if the parent is restarted). Note that this behavior is similar to how things work with the classic Akka actor API.
If, for a reason or another, you’d like to keep the state of the children intact or in other words to prevent those actors from being recreated, this can be achieved by placing the supervision strategy inside of the setup call, after having created the children, and by using the withStopChildren flag of the supervision strategy:
| |
Note that you should think carefully about preserving child state. More often than not it will be easier to start with a clean slate than to deal with some actors being refereshed and some others keeping existing state.
Lifecycle monitoring and failure escalation
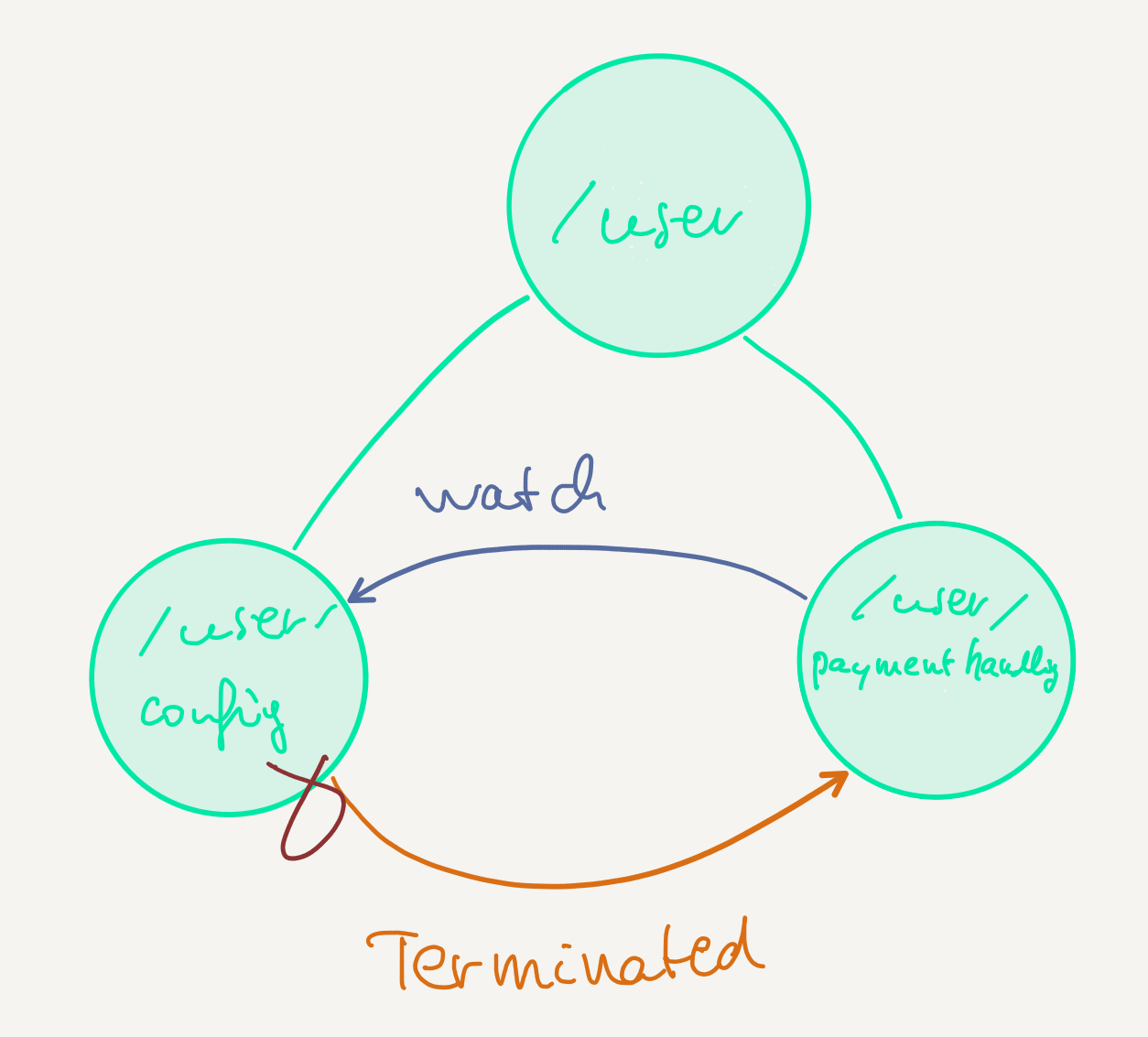
It is possible for actors to monitor the lifecycle of other actors, which is to say that they can get notified when an actor is stopped:
| |
The watching actor will receive a Terminated message containing the reference of the stopped actor being watched. We’ll talk about defining signals later — for the moment let’s just look at them as special kind of messages (which they in fact are).
Note that if we had not handled the Terminated signal ourselves then the watching actor would have thrown a DeathPactException and be stopped. This can be a useful behavior when an actor can’t function properly without another one being running, as it is the case with PaymentHandling and Configuration in our application.
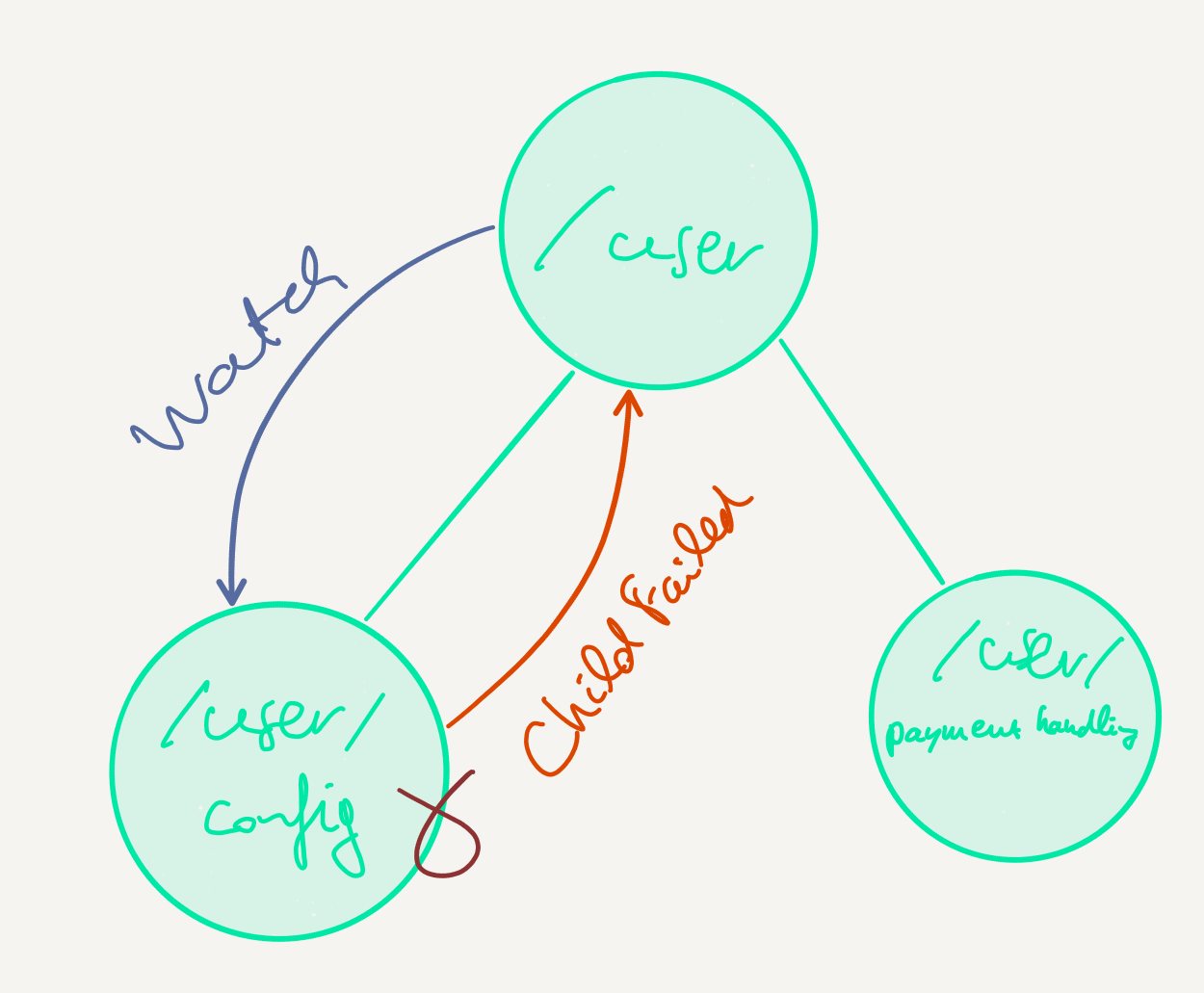
Now, the Terminated signal is received if an actor is stopped gracefully. If the watched actor happens to be a child actor of of the watching actor and it is stopped because of a failure, the ChildFailed signal is emitted instead. ChildFailed extends Terminated which also provides the reason (exception) as to why the child failed:
| |
This mechanism allows to emulate the Escalate decision that was available in the classic Akka actor API. It’s possible to simply throw an exception in the parent actor, and to behave in the same way in all parents in the hierarchy, which is to say to watch the child actor and to intercept the ChildFailed signal. It is even possible to preserve the original, underlying exception by rethrowing it or by wrapping it in an exception that allows to add more context.
Signals
Signals are Akka’s channel for notifying actors about system events. In a classic Akka system, the handling of user-defined business logic and infrastructure messages is mixed and also somewhat split between overriding methods and receiving messages, which makes it harder to understand what is going on.
It is possible to handle signals by using the Behaviors.receiveSignal method as shown below:
| |
The possible signals are lifecycle signals (PreRestart, PostStop) and lifecycle monitoring signals (Terminated, ChildFailed).
Concept comparison table
As usually in this series, here’s an attempt at comparing concepts in Akka Classic and Akka Typed (see also the official migration guide):
| Akka Classic | Akka Typed |
|---|---|
| failing actors are restarted by default | failing actors are stopped by default |
override val supervisorStrategy = OneForOneStrategy() {<br /> case _: StorageFailedException => Restart<br />} | Behaviors.supervise(...).onFailure[StorageFailedException](SupervisorStrategy.restart) |
| supervision is bound to the parent actor | supervision is wrapped around behaviors and evaluated locally |
override def PreStart(): Unit = ... | Behaviors.setup |
override def postStop(): Unit = ... | PostStop signalBehaviors.stopped(postStop: () => Unit) |
override def preRestart(reason: Throwable, message: Option[Any]): Unit = ... | PreRestart signal |
def postRestart(reason: Throwable): Unit = ... | - |
context.watch | context.watch |
Terminated(ref) | Terminated(ref) signal |
| - | ChildFailed(ref, cause) |