Akka anti-patterns: flat actor hierarchies or mixing business logic and failure handling
Contents
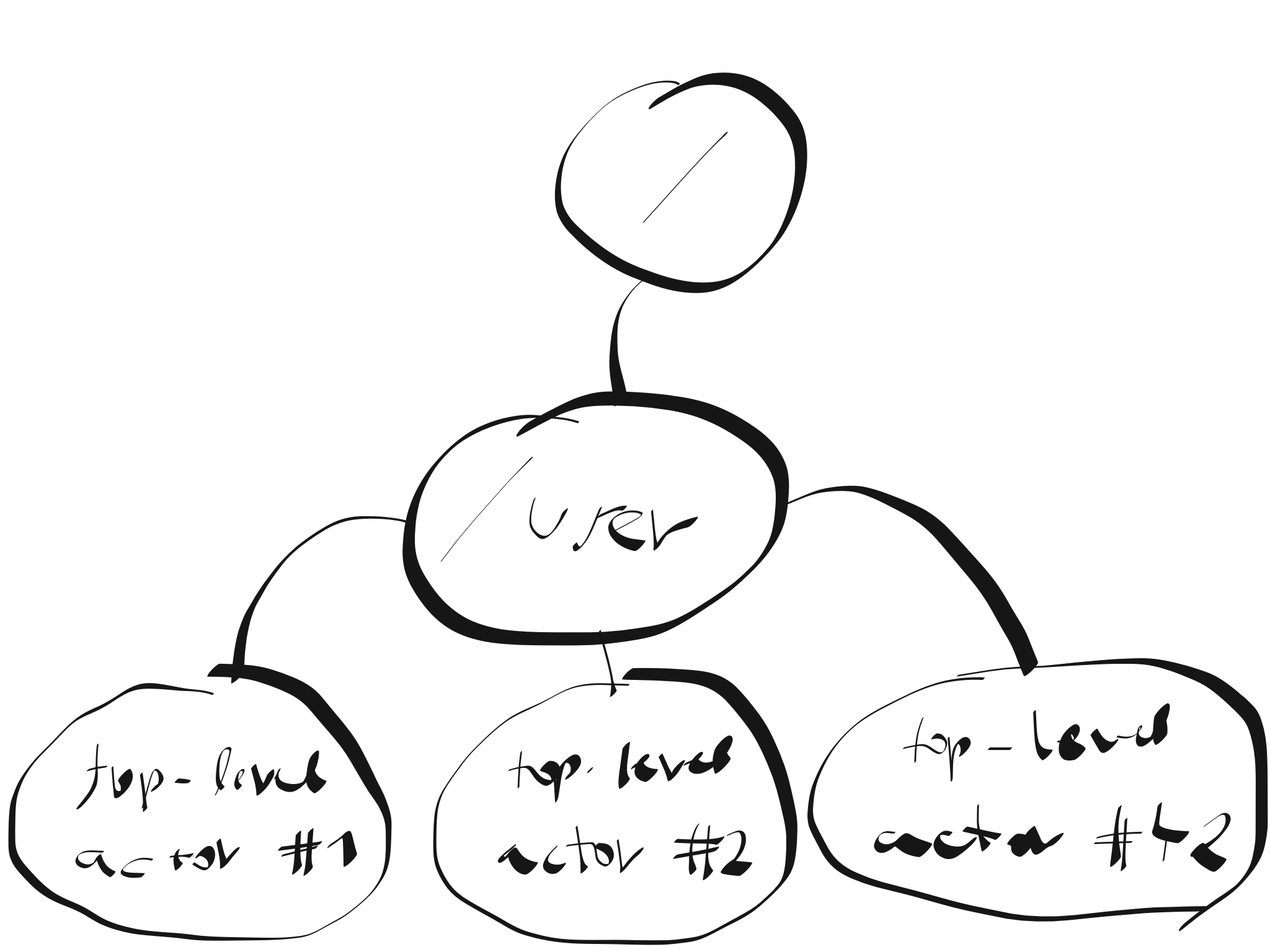
One of the fundamental ideas built into Akka is the one of failure handling through parental supervision.
In other words this means agencing actors in such a way that parent actors that depend upon the correct execution of a child to perform their work are also responsible for deciding what to do when one of the child actor crashes.
An exception thrown inside of an actor results in that actor crashing, prompting its parent to decide what to do, which it does using a SupervisorStrategy. You should not be writing defensive try...catch blocks inside of an actor - except perhaps for a few rare cases, this too is an anti-pattern! Instead the idea is to let it crash and handle failures through another channel entirely.
Why supervision?
Why? Well,
Repeat after me "Errors should be handled out of band in a parallel process - they are not part of the main app" https://t.co/5RaHPvY4r0— Joe Armstrong (@joeerl) June 7, 2016
Your main business logic should not concern itself with failure handling. Mixing these separate concerns calls for increasing the complexity of your actors (or software at large, actually). These are two different battles: the one of getting the progam to do what it should do, and the one of getting it to come back to life should something bad happen.
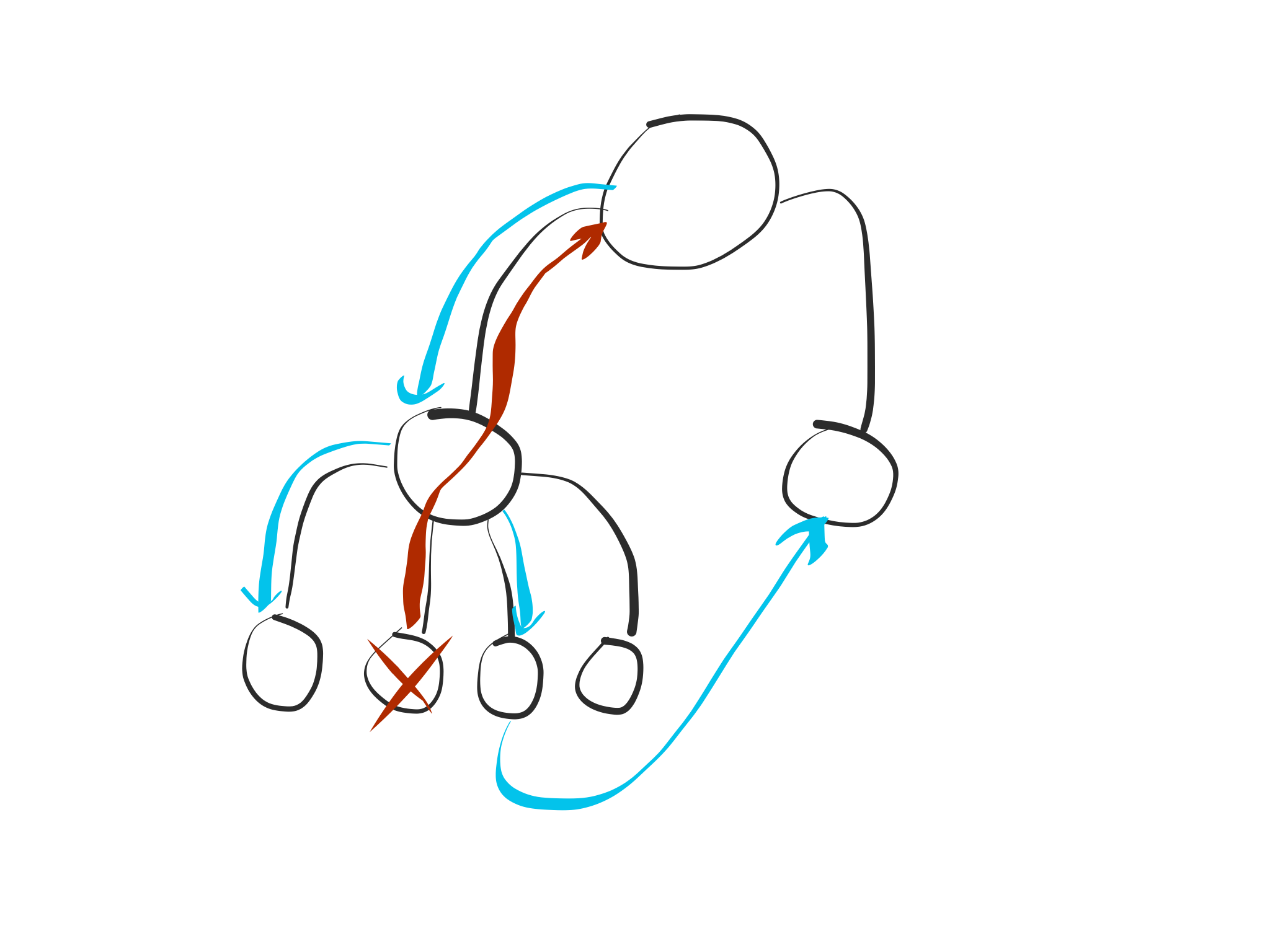
Handling failure out of band
Actor hierarchies and the supervision strategy of a parent’s actor are the means to achieve this separation. A supervision strategy gets the exception that caused the child actor to fail and then gets to decide what to do next:
- resume the child, loosing the faulty message
- restart the child, loosing any child state (except if there’s a persistence mechanism in place)
- stop the child
- escalate the exception to its own supervisor (which then decides what to do about the parent itself, and not only about its child)
Thanks to the preRestart and postRestart lifecycle hooks of an actor it is possible to let an actor do cleanup work when it is restarted. preRestart which, as its name indicates is called on an actor prior to it being restarted also gets access to the message that caused failure (if it was a message that caused failure — it is also possible for an actor to crash at initialization).
But why don’t I get access to problematic messages in the supervisor?
At an akka training I gave recently one of the participants asked an interesting question: why is there no way to get access to the message that caused a child’s crash in a supervisor? After all you might want to handle that failure differently based on the “faulty” message. This is a very good question because it goes to the core of what the responsibilities in terms of failure handling are for a supervisor. A supervising actor may not have the slightest idea of the domain of one of its child actor, therefore, if the supervision mechanism allowed to get a hold on individual messages of a child then the logic of that child would start to leak into the parent - suddenly the parent would need to know much more about the child’s domain and inner workings which is a less-than-ideal situation.
The better approach, as mentioned earlier, is to let the child do its own cleanup work in the preRestart handler - it could for example choose to send a faulty message for inspection to a third-party actor. Note that dividing responsibilities is but one of the reasons why you wouldn’t want supervision to have access to individual “faulty” messages. The entire notion of “faulty” message is also quite dangerous: who is to say that one message in particular caused a crash versus the accumulation of faulty state in general? ## Build hierarchies
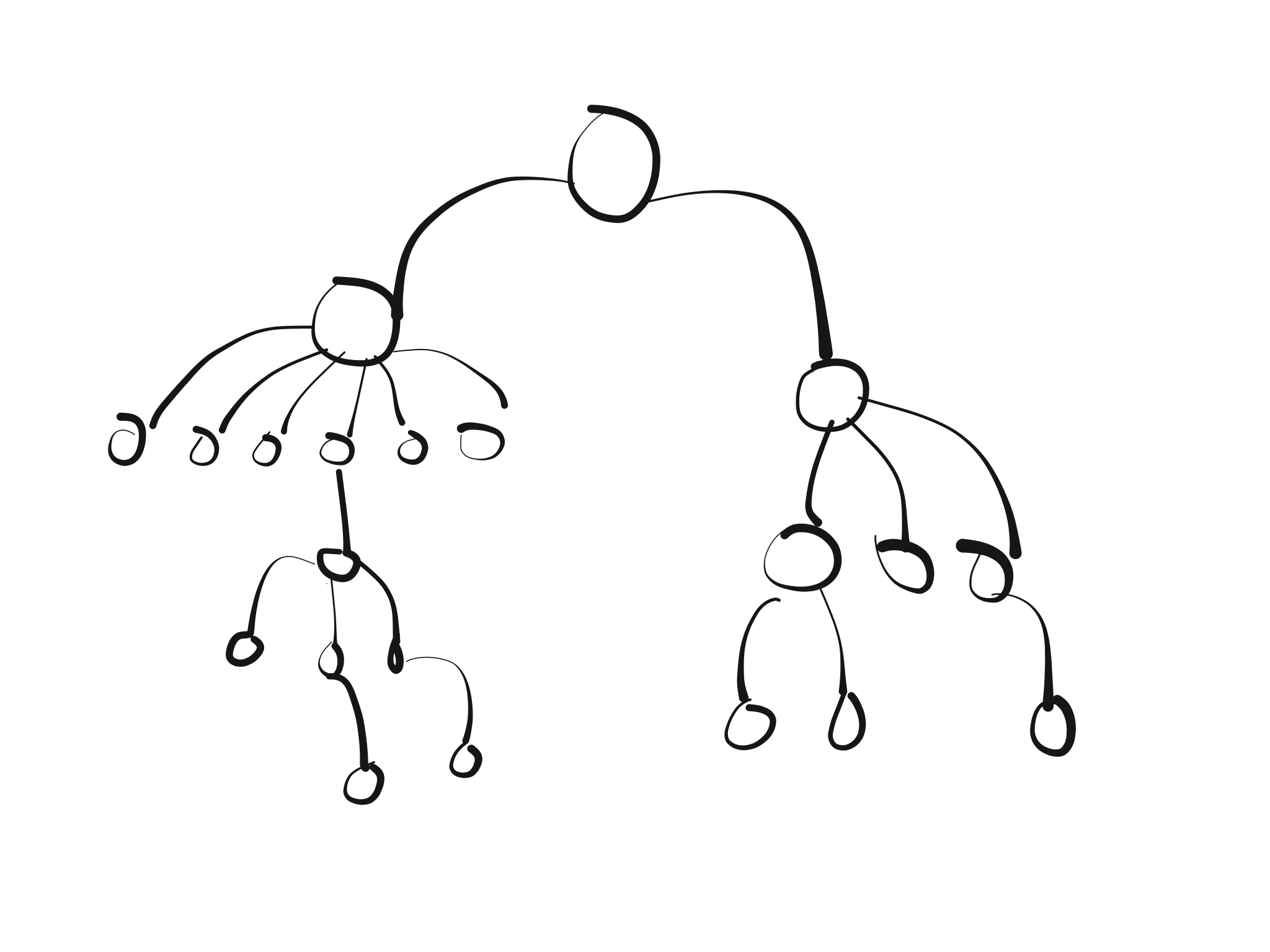
Aiming at building hierarchies forces you to think of actors in terms of responsibilities and dependencies: what other actor does this actor need in order to do this work? Is it the only one that directly depends on it, or is the dependency stronger as with other actors? Which actor has enough knowledge to reply to “clients” of this other actor? Note that there’s also a different type of supervision, the so-called Death Watch, that lets actors watch the death of other actors (and then decide to commit suicide too, or to take another action), which can be quite useful in case of strong dependency.
Check out the excellent book Reactive Design Patterns to learn more about fault tolerance and recovery patterns. Last but not least, some of the components that you build may only have one single hierarchy (for example if all actors are truly peers that talk to one another). This is fine, too - just do not let them be children of the user guardian, but roll your own supervision instead. Chances are high that in this case you will need custom supervision behaviour.