Akka anti-patterns: shared mutable state
Contents
When I work with clients on designing actor systems there are a few anti-patterns that seem to make it into initial, non-reviewed designs no matter what. In this series of short articles I would like to cover a few of those.
Anti-pattern #1: sharing mutable state accross actors

Even though the Akka documentation points this out in various places, one of the favourite anti-patterns I’ve seen is use is sharing mutable state accross actor boundaries.
What do I mean with this? Well, let’s have a look at the following actor:
| |
This actor has some state (the stateCache) that presumably hold information that it needs in order to function.
By sending it the GetState message, this state is passed verbatim - in other words, by reference - to the sender requesting the state through the State message.
So what’s the problem here exactly?
The actor model is a model, not a framework
The actor model provides the illusion that inside of an actor, everything is single-threaded. One message is processed after another, there is no way that two messages could access an actor’s inner state concurrently and therefore it is perfectly fine to modify mutable state inside of an actor as a result of receiving a message.
Well, except if you share the mutable state of an actor outside of that actor. If you do this (for example as shown in the code above) then there is no guarantee that another actor will not concurrently try to access or modify said state. And suddenly the illusion falls apart and all of the nice guarantees provided by the actor model no longer hold true.
“I know”, you’ll say, “but I promise I will only read from this state in other places”. That’s cool for your actor and all, but it is not going to help you, because:
One thread is like no other
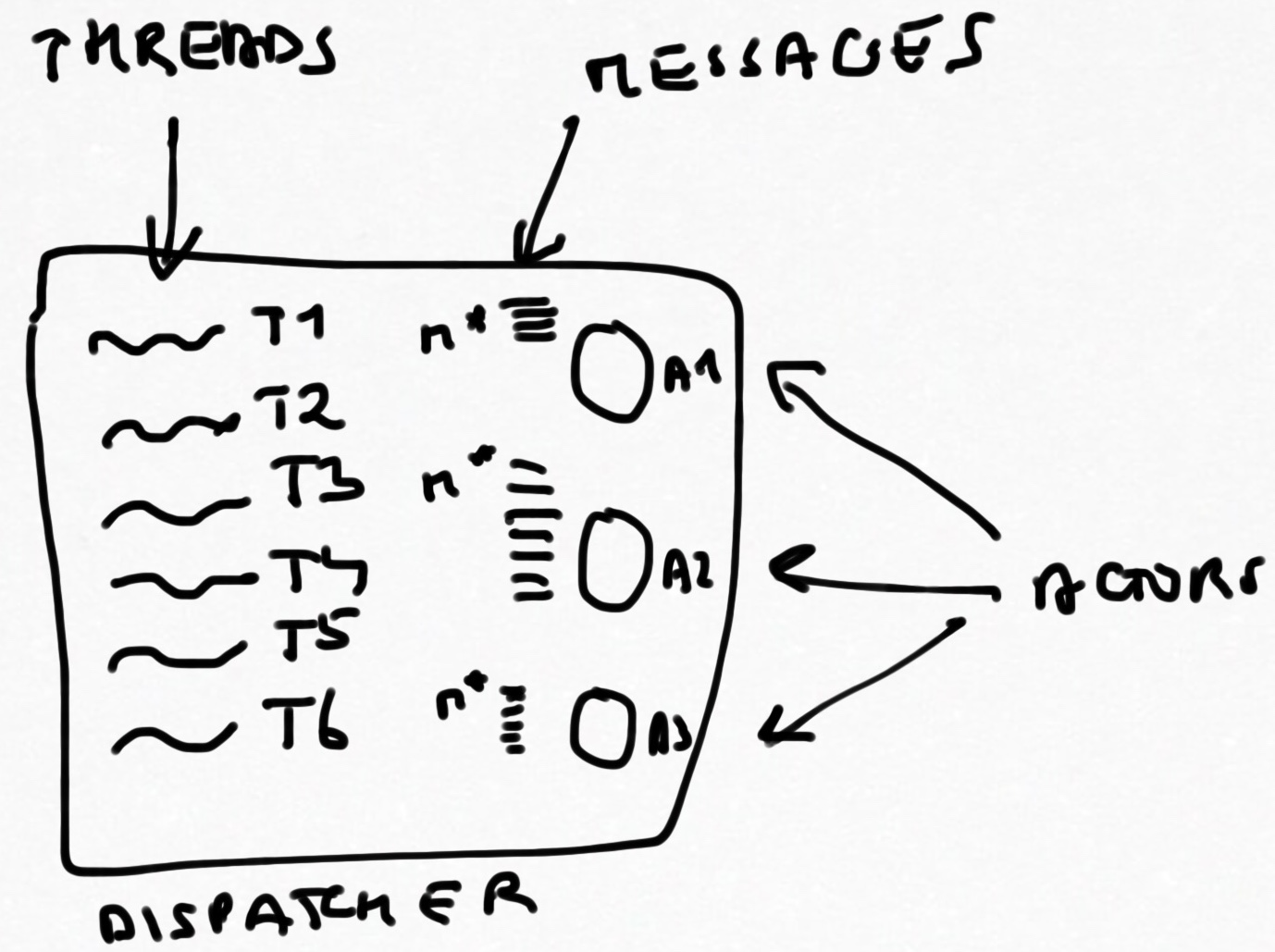
Internally what makes Akka Actors “tick” is a nifty little thing called a dispatcher. Every actor has a dispatcher, by default the same dispatcher is shared accross the actor system but you can use specific and separate dispatchers for individual actors if you would like.
The dispatchers job, roughly speaking, is to distribute the work (the messages) of one or more actors accross a number of threads. The default dispatcher is backed by a ForkJoinPool (very nicely explained here) and therefore juggles several actors and threads. This means, amongst other things, that subsequent messages processed by an actor may not necessarily be handled by the same thread.
Ergo, if you share the mutable state of your actor outside of your actor and hope that by having a reference on the state you will always be able to read the latest version of whatever data you’ve shared, you are in for a bad surprise given that multiple threads will see different versions of your shared mutable state.
“I know”, you’ll say, “but I will use a ConcurrentHashMap and everything will work then, right?”. Wrong.
Mind the gap
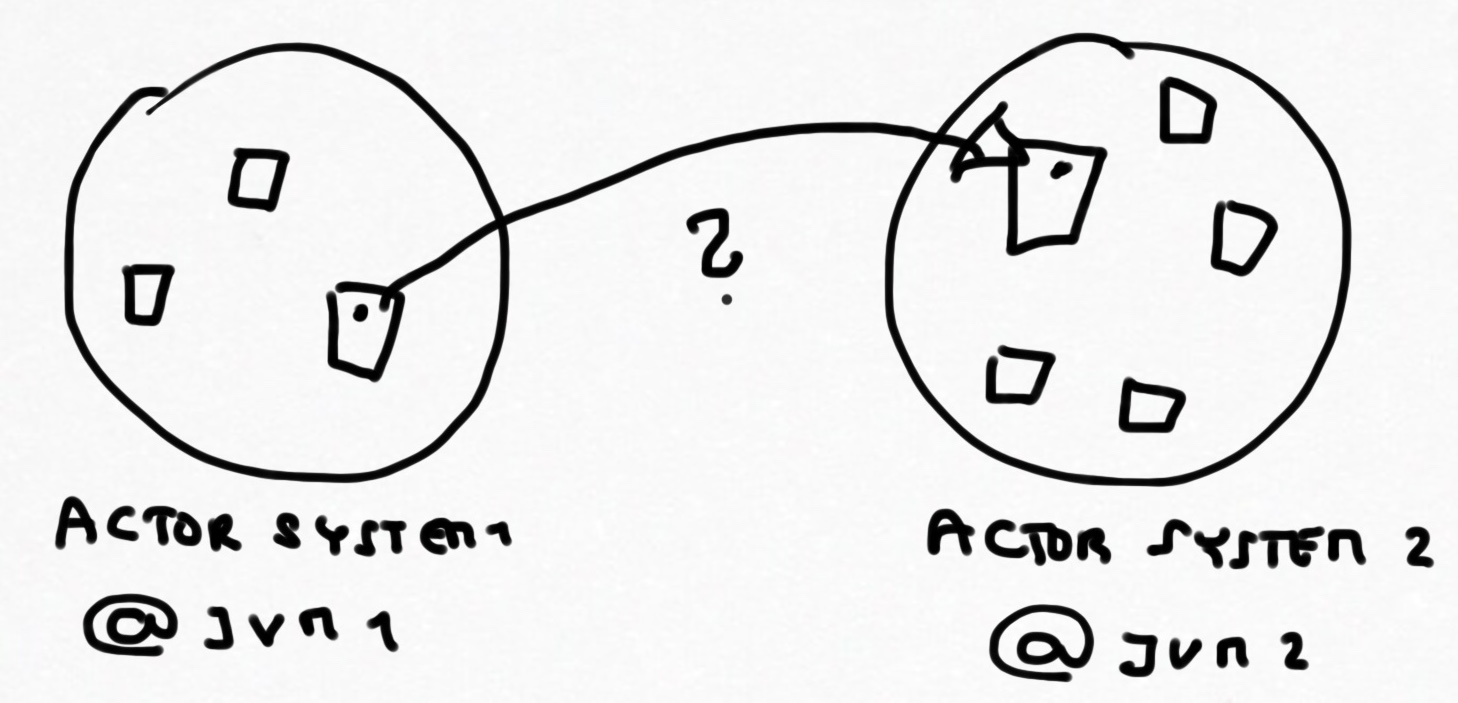
One of the nice things about the actor model is the notion of location transparency which is, to put it simply, the ability to interact with actors without having to take into account where the said actors are running. They might run inside of the same ActorSystem, inside of the same JVM or in a clustered, networked environment - when building the actor system, this should be all the same to you. Deployment is merely a matter of configuration. (Well, almost - when working in a clustered environment, you often may want to do more such becoming aware of a node entering or leaving the cluster, but in principle if you are only interested in scaling out then you do not even need to be intimately aware of this either.)
So what happens then if your ConcurrentHashMap is shared in a message accross JVM boundaries or network boundaries? How does it get serialized? How does concurrency get serialized?.
The answer is simply that it doesn’t. There is no magic mechanism that makes the ConcurrentHashMap cluster-aware and spins up distributed locks (which would be a performance disaster, by the way).
Therefore:
Simply do not share mutable state accross actors, period.
The most frequent reason I am given when asking why the decision to share state was taken is a fear of the overhead introduced through copying the state (maps or larger data structures especially). To which my answer is always the same: do all actors involved in the sharing need to know absolutely everything?
Often times, they do not - or if they do, maybe it is time to revise the actor hierarchy so as to size the responsibilities of a single actor down as much as possible (I’d be happy to help you with this, by the way). Which is to say that designing the actor system and the protocol (after a healthy event-storming session) are probably the most important activities to do when starting to work with the actor model. And once you have a sound actor hierarchy and message protocol, you’ll see that the need for shared mutable state has faded on its own.
Stay tuned for more anti-patterns to come up!