One step closer: exploiting locality in Akka Cluster based systems
Contents
When it comes to the latency of processing a request in a distributed system, everyone knows (or should know) that doing things over the network is the most expensive thing you can do (alongside with disk reads):
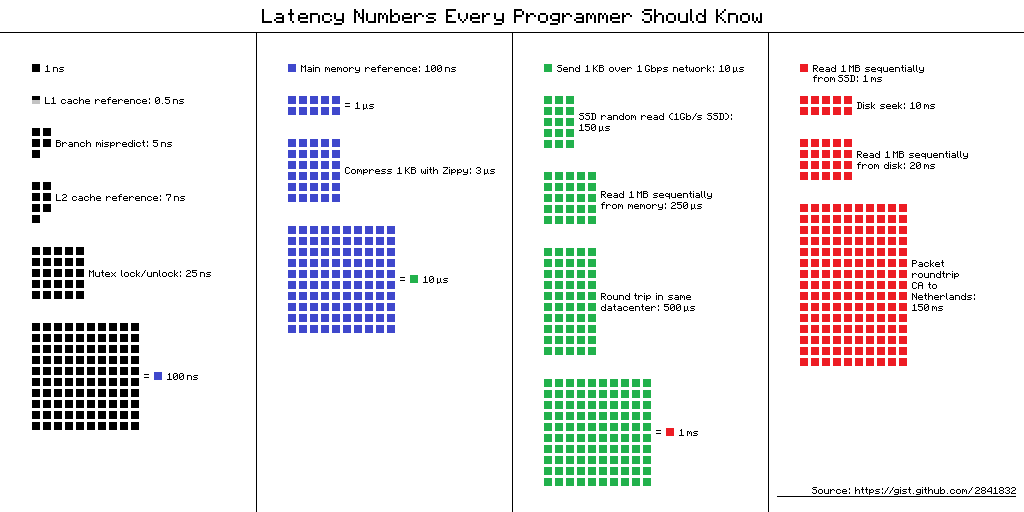
Modern architectures have recognized this and will favor keeping data in memory, avoiding the need to go to disk or to the database, when consistency requirements allow for it. With Akka Cluster Sharding combined with Akka Persistence, it is possible to keep millions of durable entities in memory, reducing latency to a large degree.
Shards Regions are the gateway to sharded entities (i.e. the actors under management of Akka Sharding). They exist on each node partaking in the sharding, resolve and then cache the location of a shard thus allowing to route messages directly to the appropriate node in the cluster:
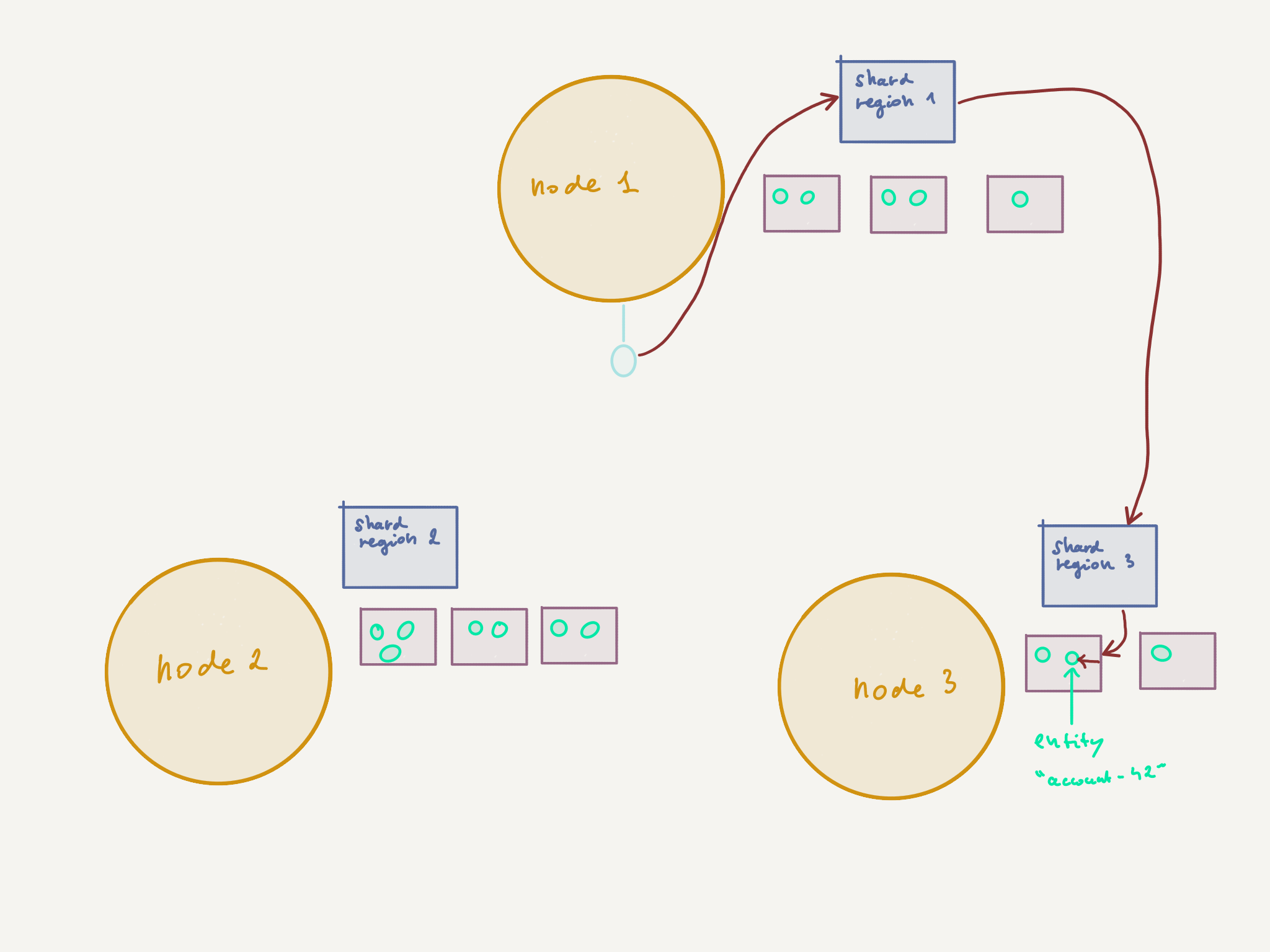
In order to send a message to a sharded entity, the message must first be sent to the local Shard Region which forwards it to the appropriate Shard Region (the one holding the shard of the target entity), which in turn forwards the message to the shard, which then forwards it to the target entity. Messages need to contain the identifier of the target entity and sharding needs to configured in such a way that it is possible to extract the identifier from a message as well as to generate the shard identifier. A very common approach is to take the absolute value of the hashCode of the entity identifer modulo the number of shards.
With a balanced system (i.e. there are more or less the same amount of shards and sharded entity on each node), there’s roughly a 1/3 chance of not having to send the message over the wire, versus 2/3 chance of having to do so. Yet on the other hand, Akka Cluster Sharding provides automatic failover and resource distribution so that’s a fair price to pay.
There are, however, a few scenarios where network hops go to waste. Let’s consider the following application design involving a cluster-aware router.
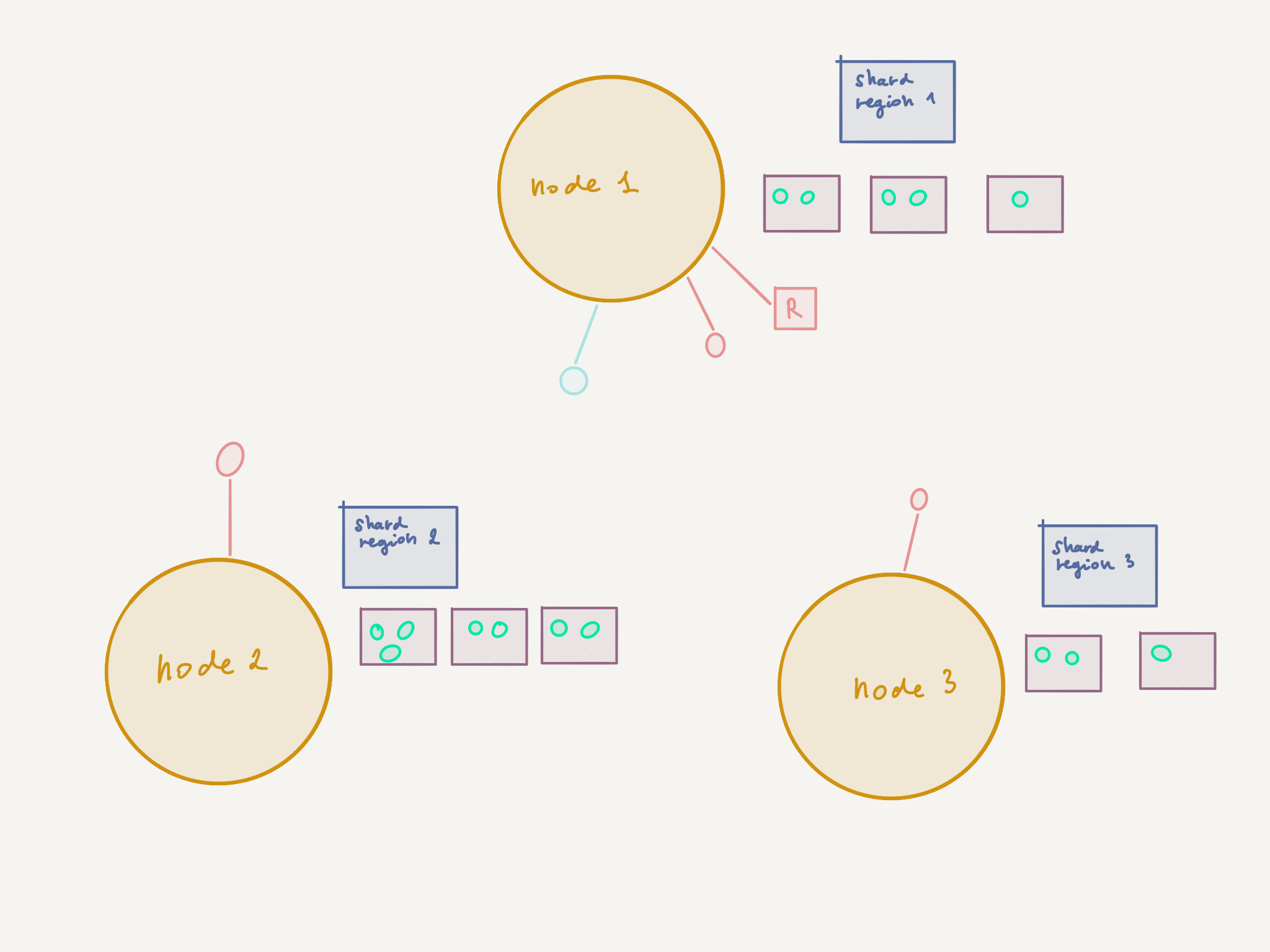
In this design, nodes with specific roles each have a routee that takes care of handling incoming requests (for purposes such as validation, enrichment, or perhaps because the routees implement etc. — in short, responsibilities that lie outside of the domain of the sharded entities). It is those routee actors that are communicating with the sharded entities.
With this design, the path of messages may become quite involved:
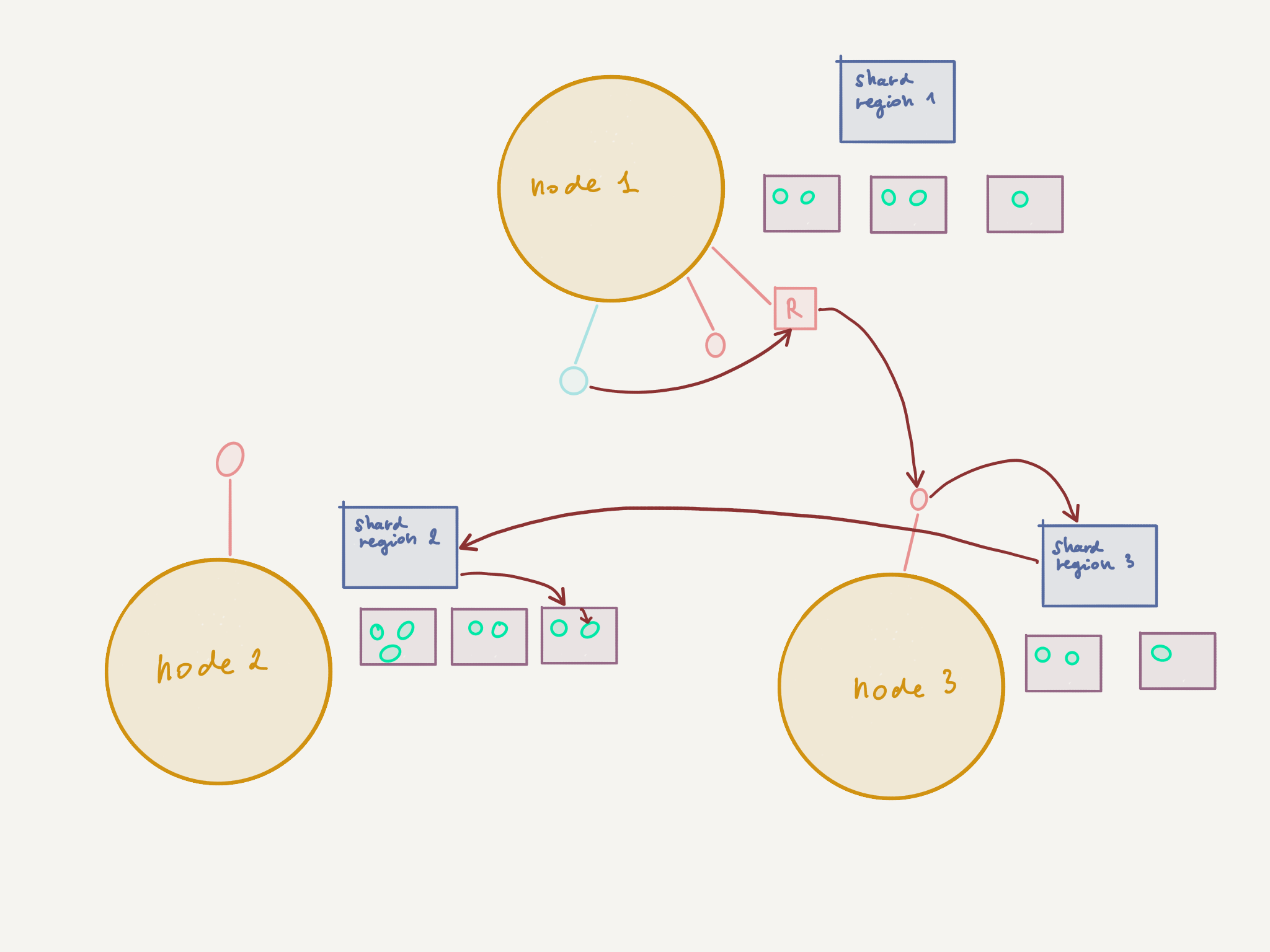
If we’re unlucky, then this “worst-case” scenario may occur:
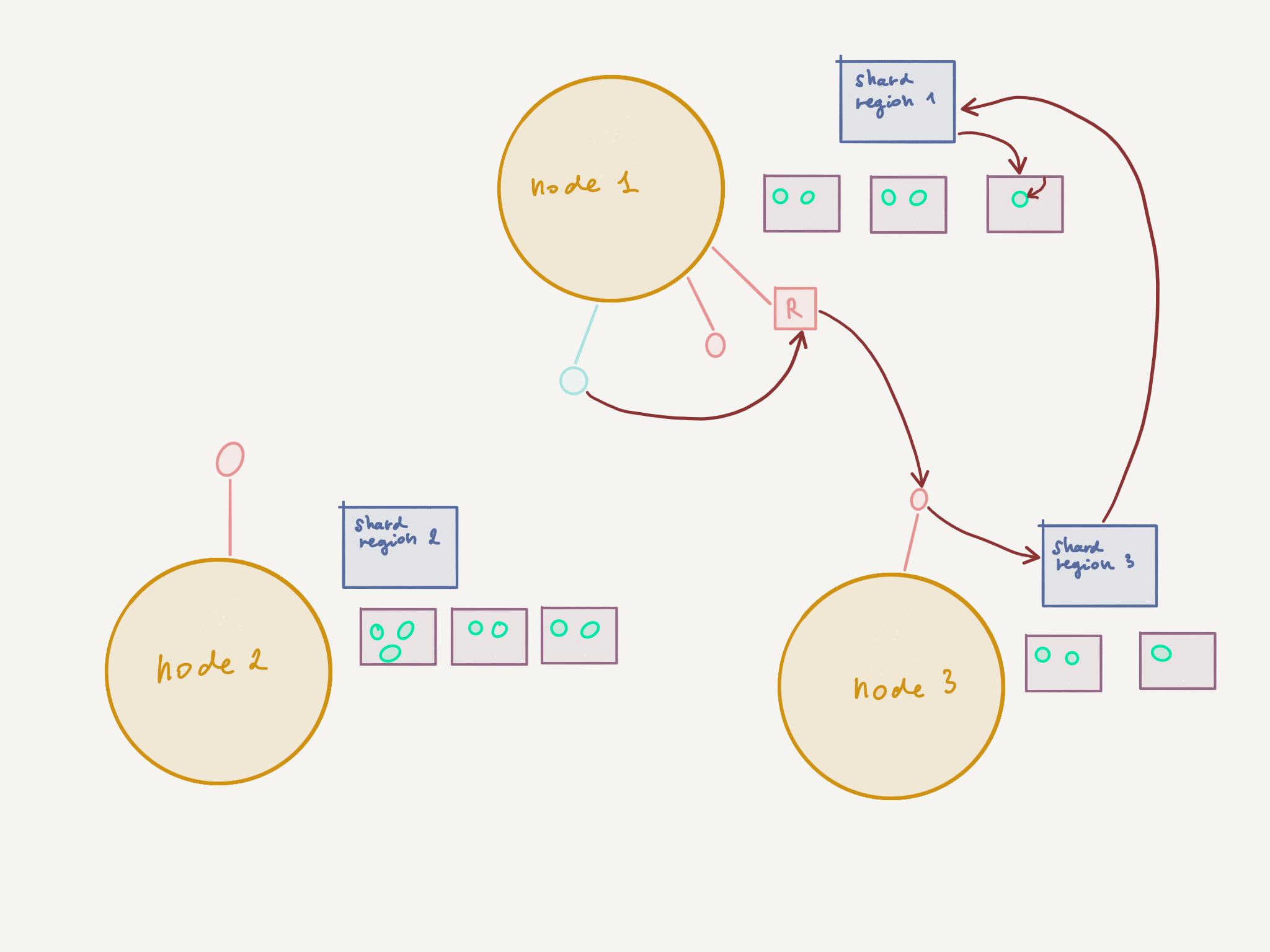
Let’s see what happens in the second case:
- The router on
node 1decides to route to the routee onnode 3(round-robin or random routing logic) - The routee on
node 3in turn communicates with the Shard Region onnode 3, which knows that the sharded entity is deployed onnode 1 - The message is sent once again over the network over to
node 1where it finally reaches its destination
In this unlucky scenario, we pay the price of two unnecessary network hops. And this is without counting possible replies from the sharded entity on node 1 to the routee on node 3, should the design require this.
So, if you’re in such a situation, what can you do? Well, one way would be for you to stop building distributed systems, regain your sanity, realize that technology doesn’t bring happiness and go live on a farm, growing your own organic food.
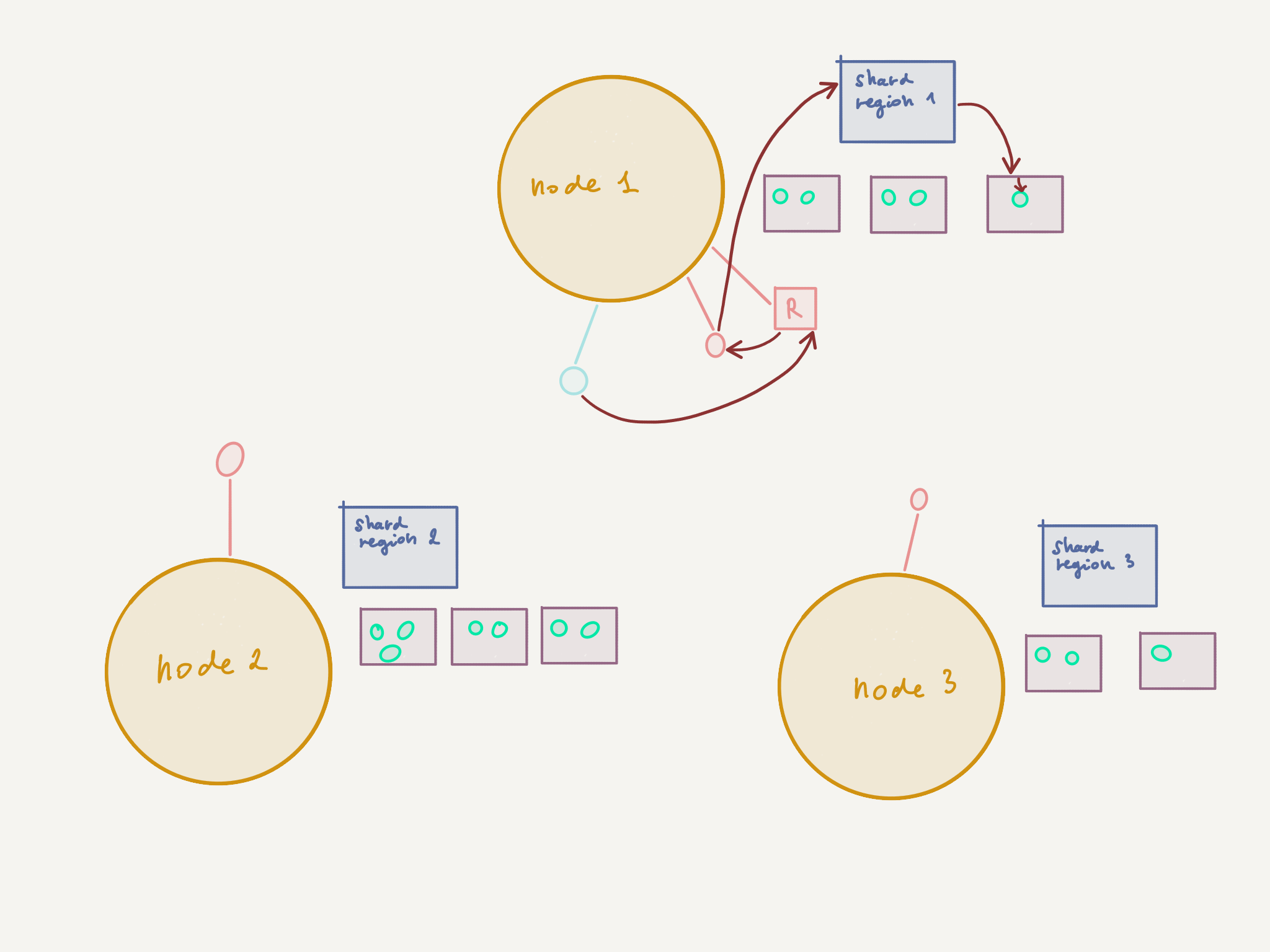
In the unlikely event that this course of action isn’t something you would enjoy, then you could alternatively try out this new library that I’ve built just for this purpose. The library provides a ShardLocationAwareRoutingLogic (as well as a ShardLocationAwareGroup and a ShardLocationAwarePool) which ensures that the router will pick the routee closest to the sharded entity, resulting in a much happier scenario:
What’s next?
The akka-locality library is just in its infancy - the aim here is to add more mechanisms that allow to help reducing unnecessary network traffic in real-life Akka applications, without having to rewrite them in part. I’d be happy to hear from you if you can make use of this library and if you have any feedback.