Tour of Akka Cluster – Eventual consistency, persistent actors, message delivery semantics
Contents
In Tour of Akka Cluster - Akka Distributed Data we looked into building a reactive payment processing system using Akka Distributed Data as a means to provide master-master replication to the order storage component. We did not, however, ensure in any way of form that the system as a whole could withstand individual node crashes. In this article, we will explore options for making the Reactive Payment Processor fault-tolerant.
Evaluating the existing design in the light of redundancy
Let’s make a thought experiment and see if our current design is fit to be “upgraded” in the light of redundancy. Let’s suppose we have made the validation process redundant, so that it would take place on any node (not just the node on which the order was first registered). This way, should the order receiving the node fail, we would still be able to continue validation and processing (so long as it wasn’t the node also handling the particular acquring bank).
One interesting scenario to think about is to see what happens if validation results were to differ on two nodes (for example, different versions of the validator running on these nodes). Remember the order lifecycle from the previous article:

Let’s see what happens in the case of diverging validation results on two nodes:
- The order is received on N1. The
OrderHandlerregisters theNeworder with the replicated order storage - Validation is performed on N1 and N2
- Validation on N1 yields
Rejected, validation on N2 yieldsValidated. - The
OrderHandleron N1 is notified of the change of statusNew->Rejected, and replies to the client that the order has been rejected - The
Executorfor this order’s merchant acquiring bank, running on N3, is notified of the change of statusNew->Validatedand starts to process the order - On N1, the
OrderStatusCRDT is merged, as a merge resolutionValidatedwins. TheOrderHandlerfor the order is notified of the change, but it is already too late (in the sense that it has already replied to the client)
That doesn’t look quite right and is not really a scenario we would like to happen - how did we get here?
The problem is that, while attempting to introduce redundancy, we are now in a situation wherein we can have conflicting results on separate nodes which get merged. Akka Distributed Data does ensure that this happens and that a merge will always work, which is why we talk about strong eventual consistency. So far, so good. The issue in our case is that we use eventual consistent data as processing instruction for interacting with other systems (the client or the acquiring bank).
If we would like our system to work, then, it would need to fully embrace the eventually consistent nature of the OrderStatus CRDT. What this means in practice is that each actor that relies on status change nofications needs to have the ability to “course correct” if it receives new, possibly conflicting, instructions. Or in other words, it is not enough for the OrderStorage component to be eventually consistent - the moment we embrace eventual consistency, our entire downstream system needs to be eventually consistent as well.
Eventual consistency is a property of the entire system, not of a single component
In our situation, we need to do either one of those two things:
- we would need to cancel the executed order in the acquiring bank - that is to say, to issue a compensating transaction - after changing the outcome of the merge resolution in our CRDT
- the
OrderHandlerwould need to inform the client system that after all, the order has not been rejected, but processed.
It is unlikely that a client system would handle this type of rollback scenario very well, nor would we want it to have to handle it - it would not be the best for credibility of our payment processing gateway. If we are to continue down this path, we will need to issue compensating transactions to the acquiring bank system. Additionally though, we will need to take care of tracking whether we have gotten ourselves in such a situation in the affected actors and make sure we do not forget about it in case of a crash. All in all, this might not be a very clean solution to put into place.
In the rest of this article, rather than pursuing this type of redundancy-based design, we will look at a failover-based way of achieving failure tolerance.
Failover mechanisms in Akka Cluster
In our previous design, we spawned an OrderHandler actor for each incoming order which was responsible for tracking the progress of the order in our system and communicating back to the client. The orders themselves were stored by the OrderStorage component which did also take care of replication / distribution. The aspect we had not at all mentioned was the behaviour of the system in case of the crash of a node: without additional work on our part, partially processed orders would be stuck in limbo, waiting forever to be picked by a (now defunct) OrderHandler to be handed back to a client.
Generally speaking, when thinking about failover, there are a few steps that need to happen:
- detect that there has been failure;
- save the state of the failed node - preferrably so before the failure happens;
- re-create the processes that were in-flight at the time of the crash; and
- load the state again to be able to resume operations
Akka gives us - out of the box - the necessary tooling for performing each one of those steps. In the rest of this article, we will explore two key tools to enable failover:
- Persistent Actors as a means to save and recover state. This covers steps 2 and 4.
- Akka Cluster Sharding. This covers step 3.
Failure detection is something that we won’t explore in depth here, although we may revisit it in the future. If you want to get in at the deep end, then this article on the subject might be something for you.
Saving state with Akka Persistence
Akka Persistence is an extension to Akka that - as its name suggests - brings the notion of persistence to actors that otherwise live only in memory. Whilst crashes of single or multiple actors in a well-designed actor system should not put your important state at harm, there’s always this looming danger of the entire node running your actor system getting lost due to a machine crash, and your precious state with it. This is where persistent actors come in.
The underlying idea of persistent actors is to use persisted events as triggers for the internal (and external) state changes of an actor. Only when an event is known to be persisted should the state of the in-memory representation of the domain be changed. This way, by replaying all the events in order, the same state can be restored. This technique of relying on events to build state is known as event sourcing.
Anatomy of persistent actors
A persistent actor functions like a normal actor in that it sends and receives messages and has a few extensions to handle persistence. It has a persistenceId that must be unique for the entire application, and that’s used to store and retrieve persisted events. Persisted events are stored in a journal.
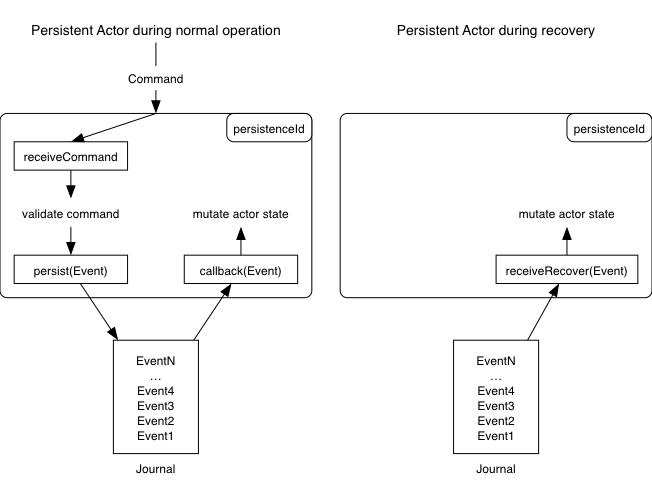
During normal operation, a persistent actor receives commands through its receiveCommand method, validates them, and then calls the persist method with the following signature:
| |
When an event is persisted successfully to the event journal, a callback handler is called for the event and then reacts, such as by changing the state of the persistent actor. This way you’re ensured that only events that have been written to the journal have any impact on the state of an actor.
This mechanism makes it possible for the persistent actor to recover its state if it crashes. After having been restarted, a persistent actor goes into recovery. During recovery, all the events from the journal are replayed in order, enabling the actor to re-create its internal state.
In terms of supervision, these persistent actors themselves need to be supervised by an actor capable of re-creating them in case of failure or system restart.
Designing protocols suitable for persistence
Let’s introduce a new Merchant actor that will be responsible for dealing with the orders of a specific merchant. Since our payment gateway is wildly successful we will have many such actors in our system. The responsibility of the merchant actor is to make sure that an order, once it has reached the system, will not be lost and eventually processed. It is, in essence, replacing the OrderStorage actor that we used previously.

When it comes to designing protocols for persistent actors, it is very useful to think in terms of commands and events: a command is what you’d like the actor to do, an event records the fact that something has been done. As a convention, then, commands should be worded in the present / active tense and events in the past tense. For example, the following would be an excerpt of the protocol of our Merchant actor:
| |
Note how the events need not carry the entire breadth of attributes over every time. The initial order data is captured in OrderCreated (by re-using the StoredOrder from the OrderStorage actor that we no longer use). Changes in order status or additional attributes (such as the bankIdentifier) are captured through lightweight events.
Implementing a persistent actor
Let’s go ahead and implement a part of the persistent Merchant actor. A full implementation can be found in the source code of this article.
| |
The state of our merchant actor consists of two maps: one to keep track of the clients and one to keep track of the orders. Note that, in case of crash, the orderClients map together with its ActorRef-s may prove to be obsolete (the Client actors having vanished as well). If we implement a blocking HTTPS API for the clients, then the call would be interrupted / failed in any case and they would likely need to retry anyway - this is a scenario that we’ll adress later on.
Let us walk through the implementation of the ProcessNewOrder command. We need to handle this command in receiveCommand, and the event in receiveRecover:
| |
In receiveCommand, we turn our command into an event and call persist. This method expects a callback function to handle the successful persistence of the event, in which we update our internal state and trigger the validation of the order. Note that it is safe to use the sender() in the callback above: this is possible because Akka guarantees that there won’t be any other message being processed by the persistent actor so long as the callback isn’t called.
In receiveRecover, we handle the recovery from a crash by updating our internal state. Note how we do not populate orderClients (there is no sender in this context!) and how we do not triggger validation again.
We could proceed and implement all of the command / event handling this way, in two separate methods. What we would observe, however, is that the implementation of the callbacks in receiveCommand and the event handling in receiveRecover have quite some overlap. Instead, we can refactor these by introducing a handleEvent method and use the recoveryFinished marker to check whether or not to execute side-effecting operations:
| |
More on persistent actors
Persistent actors offer a robust mechanism for saving state. Instead of saving the data itself (as in a traditional database or key-value store) we instead save a sequence of events which we then replay in sequence to rebuild our state during recovery. There are quite a few things that we haven’t considered here and I do encourage you to check out the Akka documentation on persistent actors. You’ll want especially to familiarize yourselves with snapshots as a mechanism to speed-up recovery, choose a storage plugin and most importantly pick a serialization format (whatever you do, do not use Java serialization which is activated by default).
Message delivery semantics
If you remember the previous article, the Executor for a specific acquiring bank is not necessarily co-located on the same node as the node receiving and processing an order. Previously we relied on Akka Distributed Data to distribute orders accross nodes and let the nodes pick the orders that were relevant for them, based on the knowledge that they were in charge of the execution for one particular acquiring bank. With our new design, we are now in charge of sending the order for execution to the correct node.
Let’s sidestep the question of how we make sure that the right orders get to the right node for the time being, and focus on the sending part. It is important that we do not end up with orders being executed twice, therefore let us explore a little bit how we could achieve this.
Making sure the executor does not get ExecuteOrder messages twice
Let’s assume we get the following commands in sequence, and then a crash:
ProcessNewOrder
ProcessOrderValidated
<<crash>>
During recovery, the following events will be replayed:
OrderCreated
OrderValidated
<<recovery finished>>
So far, so good. But with our current implementation, this is exactly as far as we will get. Our order will be stuck in limbo forever and not be processed any further. This is because during recovery, we do not trigger any side-effecting operations such as handing an order over to the executor - we wouldn’t want already executed orders to be executed again.
Indeed, it would be possible to get in the following situation:
- The order is validated and persisted as such on node A
- The order is sent to the
Executoron node B - Node A crashes
- Node B sends the acknowledgment to a crashed node A which never receives it
- Node A recovers
- ???
What do we do now? if we systematically reprocess all validated orders, we could end up with orders being executed twice, which is hardly what we want. Alternatively, we could introduce an acknowledgment mechanism so that the Merchant actors knows that the order has been received by the executor, the absence of which means that the order must be resent:
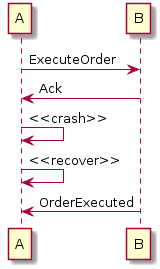
In this scenario, we receive an acknowledgement, crash, recover, and know that we don’t need to resend the order because we already have received an acknowledgment. Good! But what about this:
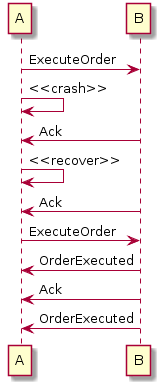
In this situation, we are not that lucky and our acknowledgment gets lost in the void that exists between the crash and recovery of node A. No problem, then: we can just retry acknowledging as long as node A acknowledges our acknowledgment, correct?
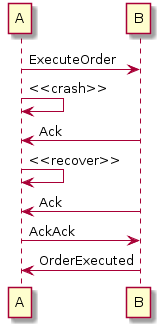
Great! We’re done now, and can go home. Or are we? We haven’t let B crash yet:
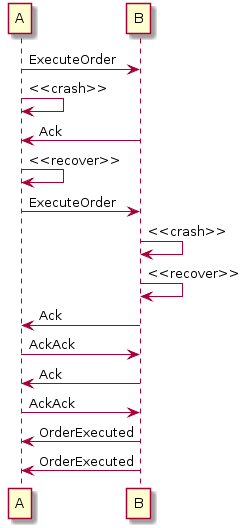
In this scenario, node B crashed before it had a chance to send an acknowledgment to A, which then assumes that B hasn’t received the ExecuteOrder message, and re-sends it, leading to the duplicate execution of the order.
We could go on trying things out for a long time. And I haven’t even started touching other failure scenarios such as messages getting lost because of network errors, or messages being stuck somewhere in a buffer and then eventally getting delivered, etc.
Try as you may, there simply is no way to guarantee that we can both:
- guarantee that B sees our
ExecuteOrdermessage at least one time; and - guarantee that B sees our
ExecuteOrdermessage at most one time
In other words, there is no way of providing exactly-once message delivery guarantees. Anyone who claims they have built a system that provides these guarantees either doesn’t understand the problem space, or mean something slightly different.
Indeed, the only way forward is to acknwledge the reality that if we want a message to be received at least once, it may as well be received more than once and possibly out of order. Therefore, we have no choice but to make this a viable scenario at the receiving side (in our case, the `Executor).
Idempotency on the receiving end
An operation is said to be idempotent if it can be applied multiple times and still yield the same result. For example, the operation “multiply by one” is idempotent:
42 * 1 = 42
42 * 1 * 1 * 1 * 1 = 42
In our case we must ensure that the operation “processing the ExecuteOrder” message is idempotent.
In order to do so, we will keep track of the orders that we have received so far:
| |
We keep track of the received order IDs in a map, together with the reception timestamp. This will allow us to perform cleanup from time to time (for example, once a day - because we assume that we won’t have a downtime that lasts longer than a whole day, or else we’d be in trouble anyway). We can use the new (since Akka 2.5) Timers API for this purpose:
| |
The Timers API has the advantage over the scheduler that it takes care of cancelling the timer when the actor is shutdown. Each timer has a key, and so if a timer with the same key as an existing timer is started, that timer will be reset - which is quite useful when an actor restarts.
Note that what we have not yet done here, but still need to do for our system to work well, is to make this actor persistent as well - or else, the idempotency mechanism will only work so long as the receiving node doesn’t crash.
At-least-once delivery semantics on the sending end
In order to make sure that our messages make it over the network, we need to retry sending them until we get an acknowledgment. This is quite boring to implement, which is why Akka has support for it out-of-the-box.
In order to implement it in our case, we need to do a few modifications:
- the
ExecuteOrdermessage needs to carry adeliveryIdthat is generated by Akka - we need to use the
delivermethod instead of a simpletellwhen sending messages to theExecutor. We will do this after persistingOrderValidated - the
Executorneeds to send back a confirmation message to theMerchant - the
Merchantneeds to call theconfirmDeliverymethod
All in all, this is how it looks like in the Merchant:
| |
And in Executor (which is still not persistent, by the way):
| |
Effectively-once delivery semantics overall
When a sender with at-least-once delivery semantics is coupled with an idempotent receiver (which in our case needs to have some type of durability in order to implement idempotency) we get “effectively-once” delivery semantics:
I'm coining the phrase "effectively-once" for message processing with at-least-once + idempotent operations.— Lgd. Viktor Klang (@viktorklang) October 20, 2016
Summary
This concludes the second part of the Tour of Akka Cluster series. We started by evaluating whether the design from the first article was easy to evolve so as to make it failure tolerant via redundancy and discussed that we would need for our entire system to support eventual consistency for this to work out. We then started to look at another design approach based on automatic failover and provided by the combination of persistent actors and cluster sharding. We then explored Akka Persistance and rewrote a part of our system with it, and finally took a sharp look at message delivery semantics.
In the next article of this series, we will continue to make our system tolerant to the crash of individual nodes by introducing cluster sharding and we will have a look at leveraging cluster-aware routers to get messages to the correct nodes. Stay tuned!
- Part 1: Akka Distributed Data
- Part 2: Eventual Consistency, Persistent Actors and Message Delivery Semantics
- Part 3: Cluster Sharding
- Part 4: Testing with the multi-node TestKit and a handful Raspberry PIs