Tour of Akka Cluster – Akka Distributed Data
Contents
Building distributed systems is hard. Pesky things like the laws of physics get in the way of maintaining state accross geographically (and chronologically) disparate systems, and, if that weren’t already outrageous enough in itself, those systems may be subject to network failures, forcing us to think about annoying tradeoffs regarding consistency, availability and the meaning of life.
One of the more interesting (well, at least from my perspective) tools in the Akka toolbox is Akka Cluster and the modules built on top of it. Through its design it acknowledges the hard reality of life, promoting a “no magic here” approach to building distributed applications and yet at the same time, takes care about many of the harder aspects of doing so.
In this article series, we will explore different components of Akka Cluster, taking the use case of a (simplified) payment processing system. This first article is focusing on the Akka Distributed Data module. As of version 2.5, it is no longer experimental and gets better with every release.
This module makes use of Conflict Free Replicated Data Types (CRDTs, in short). While there generally is a consensus that this name conveys a tremendous degree of coolness and while people get quite excited and all agree of how useful and promising those data types are when they come up in a conversation, it has been my experience that once the conversation shifts to the topic of, er, actually using those neat things in practice, silence ensues.
Let’s change this.
Introducing the Reactive Payment Processor
As a supporting use case for exploring Akka Cluster, we will build a reactive payment processor. The job of this system is to allow its clients (merchant systems) to accept payment orders (such as credit card payments for example) and to take care of all the intricacies related to processing the order so that money flows from one account to another. This isn’t done by the system itself - instead, the system places an order with an acquiring bank which takes care of executing the financial transaction.
Note that we are going to simplify things quite a bit along the way. That being said, we’ll keep the crucial aspects of such a system in place so as to be able to talk about tradeoffs and to explore various solutions and tools.
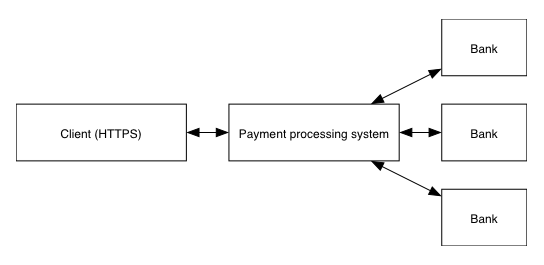
Design considerations
Since we want to build a reactive system, we want to avoid as much as possible the existance of single points of coordination - or, to put it bluntly, single points of failure. Once an order has reached our system we’ll do everything possible to handle it as fast as possible, even if a part of our data centre is on fire. We’ll need this guy, too:

Generally speaking, we want the following things out of our system:
- continue operating when a node goes away, without losing data. A node may go away at any point in time due to hardware failure or because we’re updating the system to add for example integrations with more banks as our business grows
- low latency - we want orders to be processed fast
- tracability - we need to know exactly what has happened to one order throughout its lifecycle
The lifecycle of a transaction in our simple processing system is as follows:
- the merchant places a payment order via a web API
- the order is validated and will either get executed or rejected
- the machine responsible for the acquiring bank executes the order
- the result is returned to the client
In this first article, we will operate under an important assumption, which is that the communication with acquiring banking systems is more often than not limited to one physical machine. This may be because the acquiring bank only allows the connection from one machine at the time or because of special security mechanisms (based on hardware tokens for example).
Order lifecycle

When an order first hits the system, it gets marked as New. It then undergoes validation and configuration and as a result will be enriched with more information required for its execution. Failing this, the order is marked as Rejected. Validated orders get forwarded to the acquiring bank for execution which either results in a successful Executed status or an unsuccessful Failed status. Finally, when an answer has been sent to the client, the order is marked as Done.
Components
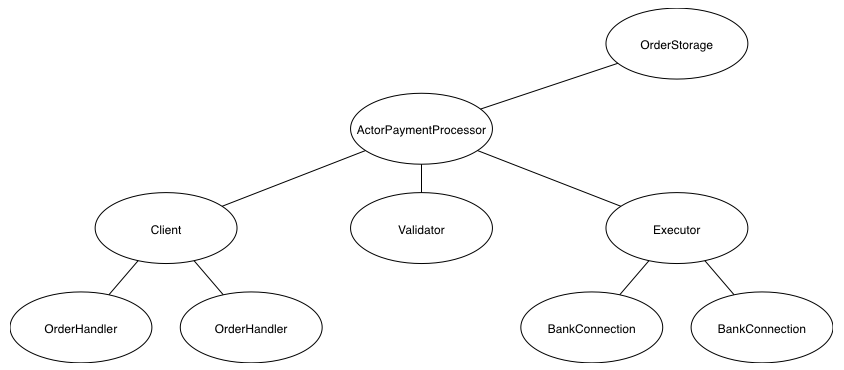
Our simple payment processor system is built around the following components:
- the
Clientaccepts incoming orders and for each one, spawns a newOrderHandler - the
OrderHandleris responsible for seeing an order through and eventually replying to theClient(who in turn replies to the actual merchant) - the
Validatormakes sure that the order is valid and as a result, resolves values related to the configuration of the merchant issuing the order - the
Executormakes sure an order gets passed on to the acquiring bank - the
BankConnectionrepresents a networked connection to a bank which eventually will signal whether the order has succeeded or failed
The source code for the application can be found here.
Introduction to Akka Distributed Data
Akka Distributed Data is a module designed to allow sharing data between cluster nodes. It is designed as a key-value store, where the values are Conflict Free Replicated Data Types (CRDTs). This allows for the data to be updated from any node without coordination due to the nature of CRDTs - the values always converge.
The replicator
The interaction with this module is done via the Replicator actor obtained as follows:
| |
In order to further interact with the replicator, we also need an implicit Cluster to be in scope, since the module expects to replicate data using it.
As mentioned earlier, Akka Distributed Data is designed as a key-value store. The keys are a bit special in nature insofar as they also encode the type of the values. In order to obtain a key for an ORMap (observed-remove map - more on this later), we proceed as follows:
| |
For the time being let’s just take the key as-is and work with it, we will revisit later the details. Note, however, that we named the Key variable using an uppercase notation which will allow us to match against it in match expressions, as otherwise, per the Scala language specification, we would match any value:
8.1.1 Variable Patterns
[…]
A variable pattern x is a simple identifier which starts with a lower case letter. It matches any value, and binds the variable name to that value. […]
Updating data
The Replicator being a simple actor, we communicate with it using a message-based protocol. In order to perform updates, we use the Replicator.Update message, like so:
| |
- The key of our distributed data, so that the replicator knows what we’d like to write. This is the key we defined earlier on
- The initial value for our distributed data, in case there’s no value yet for this key. In this case, it is going to be an empty
ORMap[String, StoredOrder] - The write consistency we expect, which can be
WriteLocal,WriteTo(number of nodes),WriteMajorityandWriteAll. In this case, we useWriteMajoritywhich will is to say N/2 + 1 nodes (with N being the number of nodes in our cluster) - An optional request object to be passed along with this update request. Since we’re going to receive an asynchronous response to this update request, this can be useful to reply to e.g. the actor that placed the storage request in the first place or a custom request object (the type is
Any) - A function to execute in order to modify the value of the data. In our case, we aim at adding a new
StoredOrderto the map, which is exactly what we do here. Note that we useStringas the type of the key, which is why we need to serialize it explicitly.
The last point might need a bit more elaboration. Let’s look at the signature of the Update message that we are using:
| |
What happens when sending an Update message with our Key is that the value of that key in the local distributed data store, which is to say the entire ORMap, will be passed to the modify function that we have implemented. Or to put it differently, in the example above we are working with a “map of maps” (the outer map being the Distributed Data Key-Value store, and the inner map being our ORMap of orders).
Ok, so we fire this message off to our local the replicator. What happens next falls in 3 categories:
- the update succeeds
- the update fails entirely
- something in between, because, hey, distributed systems!
Let’s look at the easy case, the UpdateSuccess:
| |
When everything goes according to plan, we get back an UpdateSuccess message that we can match against - specifically, using the Key of our data as well as the request type we used originally.
Next, in the category of “certain failure” we have a ModifyFailure. This is a wrapper for any kind of exception thrown while executing our modify function. This is a good indication of a programming error - this really shouldn’t fail.
Finally, in the category of “it may have worked after all but we don’t know for sure”, we have the UpdateTimeout and the StoreFailure:
- an
UpdateTimeouthappens if we didn’t get a positive acknowledgment from all the nodes at the write consistency level we expect within the timeout we configured. In our case this would mean that the majority of the cluster nodes didn’t reply within 5 seconds. This doesn’t mean that they won’t answer eventually. It may as well mean that the nodes were slow for one reason or another, or that there was a network issue. Deciding what to do if this happens really depends on the use-case and on the type of guarantees you want. - a
StoreFailurehappens if there was a problem writing to durable storage locally. Durable storage is a form of local, disk-level persistance that can be activated for specific distributed data keys as an additional protection against data loss in case of node crash.
Listening to changes
A useful functionality (that we use in the implementation of the OrderHandler component) is to listen to changes in a distributed data value. All it takes is to subscribe to notifications pertaining to a specific key, like so:
| |
We then get messages of type Replicator.Changed when something has changed:
case change @ Replicator.Changed(OrderStorage.Key) =>
val allOrders: Map[String, StoredOrder] = change.get(OrderStorage.Key).entries
// do something with the orders
There is more you can do with the replicator, such as retrieving data for a key or deleting data, but we won’t cover this here. Let’s rather look at the type of data itself.
The ReplicatedData type
So far, we talked at length about ways of interacting with the distributed data key-value store, but we haven’t adressed the elephant in the room, which is to say that the data needs to be of a specific type for all of this to work.
Let’s first have a look at the ReplicatedData trait:
| |
In order for a type to be useable with Akka Distributed Data, we need to give it a type (easy enough) as well as a merge function. Note that the type is also used in the key that we created (and then used) previously:
| |
In other words, the typed key is how the replicator knows how to deal with values of a certain kind.
The merge function is where the interesting things happen. As you can see, the merge function returns a T, and not an Option[T] or Try[T] - this is to say that the merge always works. There’s a whole family of data types, the so-called state-based convergent replicated data types (or CvRDTs, in short), for which this property holds true. One of the properties that must be respected by the merge function for this to work is that it is monotonic, i.e. that it only grows in one direction:
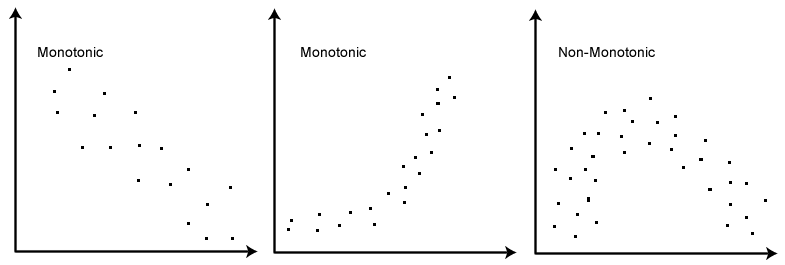
Akka Distributed Data provides a set of basic CvRDTs to work with. In our example, we use an observed-remove map which in case of concurrent updates (i.e. a merge with multiple possible values) will keep a key over removing it. As we will see later on, in our case, this is a limitation we can work with.
A nice property of CvRDTs is that they can be combined to create more advanced data types. Take for example the PNCounter which is a counter that can be incremented and decremented - something that clearly isn’t monotonic. Internally it works simply by having two GCounter-s (grow only counter), one used for increments and one for decrements, the value of the counter being the increments minus the decrements.
Other types of CRDTs rely on external input to complete the merge. For example, the CRDTs of type last-write-wins (LWWMap, LWWRegister) use clock time to figure out how to merge concurrent changes. Whilst this can be quite useful it also means that you need to have synchronized clocks accross all nodes, which can be tricky to achieve in practice (to put it mildly).
The type of CRDT to use depends heavily on the use-case at hand as well as on the setup. In what follows, we will see how to create custom data types and how to combine them with existing CvRDTs.
Multi-master replication in practice with Akka Distributed Data
Let’s come back to our reactive payment processor. We want it to be as robust as possible, not depending on the failure of a single node. At the same time, we also acknowledge one important design consideration, which is that the connection to an acquiring bank is limited to one node at the time (worry not, we will come back to this point in a further article).
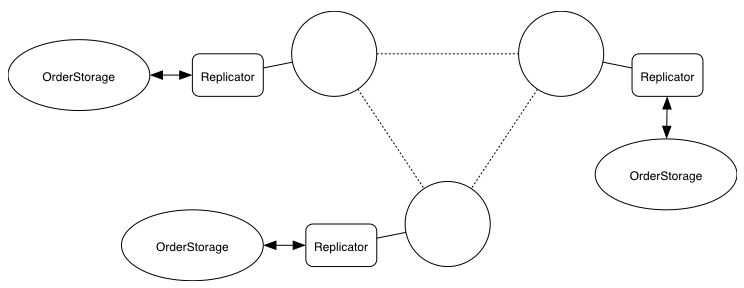
What we’ll do is that - as you may have guessed by now - replicate the incoming orders using Akka Distributed Data. For this purpose, we will need to create a custom distributed data type that represents the orders and then integrate akka distributed data with the rest of our system.
Defining our data types
Let’s consider for a moment what an incoming payment order looks like. A rather simplified version of a credit card order (for a pre-registered credit card for which the merchant system has a token) could look as follows:
| |
(MerchantAccount, CreditCardToken and Currency are AnyVal-s wrapping primitive types, for type safety).
Defining the StoredOrder data type
The incoming order alone will not be enough for us to process it - we need more information about it. Namely:
- we need an identifier to be able to uniquely refer to this order throughout the system and for traceability
- as mentioned earlier, the order will get enriched with configuration values in the validation phase to enable further processing. In our simple example, we will need to know the bank identifier of the bank that will execute this order (which is something specific to the merchant)
- in order to track how far along an order is in the processing, we need to represent its status (accoring to the lifecycle graph above)
This additional information including the original merchant order will be what we will store using Akka Distributed Data. We therefore define our own ReplicatedData type and will call it StoredOrder:
| |
As we saw earlier we need to specify the type T of the data, which is simply the StoredOrder itself. The more interesting part will be the merge function - how do we define this function so that concurrent changes always converge to one unique version? Let’s reason about our data for a bit.
The order identifier is a value that we will generate very early in the lifecycle of the order processing, possibly signalling it back to the client. We know that the identifier will not change throughout the lifetime of an order, therefore merging two orders with the same identifier will retain the same identifier.
The initial Order itself is likewise not going to change - we will not want to change anything regarding the amount, currency or affected merchant on the way through our system. Being perfectly immutable, any representation of the order will do.
The bankIdentifier is a piece of information that we only get to know about once the order has successfuly passed the validation stage. Before that, it is undefined. If we merge two orders, one of them having a bank identifier set and one having it be undefined, we will retain the version with the most information, i.e. we will keep the populated bankIdentifier Option. Note that in this example, we will suppose that the validation mechanism in all nodes will always yield the same identifier and not produce conflicting results. If that were the case, we would need to use a more elaborate mechanism to be able to tell which confiugration result “wins” by for example using version numbers for this type of configuration data.
Finally, this leaves us with the order status, which is arguable a bit more complicated. We will need to define our own distributed data type for this one. Before diving into this though, let’s circle back to our merge function that we are trying to implement here. Supposing that we alrady had implemented the status as an own ReplicatedData type, we could compose it with our OrderStatus type by calling its merge function. This leads us to the following implementation:
| |
Simple, isn’t it? Let’s look at the more advanced bit - the order status.
Defining the OrderStatus data type
In order to reason about the order status, let’s have another look at the status lifecycle for a moment:
As we can see intuitively, the arrows on this graph all point from the left to the right, suggesting that there is likely a means to define a monotonic merge function for the status. If we attempt to merge two orders, one of them having the status New and the other one the status Validated, we will want to keep the Validated status which is further down in the processing chain. There are two exceptions, that being said: Validated and Rejected as well as Executed and Failed are in direct conflict - there’s no easy way around here other than deciding which version of the reality we want to keep:
- in the case of
ExecutedversusFailedthe decision is rather easy to take - if the order was executed on one node, i.e. it has executed at least once, we will retain the status asExecuted. - in the case of
ValidatedversusRejectedwe have to consider what this means in relation to our system implemntation. If we trust that the validation is conservative, then if one node yields aValidatedstatus, then it means that we can trust this richer result. It is likely to say, for example, that the validation failed on the other node because a third-party component required to perform the validation (such as a database, for example) was not available on that node. We will therefore favourValidatedoverFailed.
All that is left to do after handling these two exceptions is to implement a merge function for an acyclic directed graph that searches for common descendants. This is the point at which you will want to get a copy of Reactive Design Patterns by Roland Kuhn with Brian Hanafee and Jamie Allen which defines such an algorithm (for a more optimistic case in which the conflicts we have can’t arise). Rather than rolling our own here, we therefore reuse Roland’s algorithm for the non-conflicting cases. You can check the implementation in the source code for this article.
Putting it all together
OrderStorage as adapter
The component in our system that will interact with Akka Distributed Data is the OrderStorage. You can think of it as an adapter from our domain to the world of master-master replication - the rest of our actors shouldn’t have to concern themselves all too much with the intricacies of replicated data types or dealing with the replicator directly. To do so, we expose the following protocol in the OrderStorage companion object:
| |
Additionally, we also want to enable other components to be notified of changes in the orders. The OrderHandler and the Executor will need to be able to do this. For this purpose, we will leverage the local event stream of the actor system and publish the changed orders:
case class OrdersChanged(orders: Map[String, StoredOrder])
With this design, from the perspective of the other actors in our system, it doesn’t matter how the OrderStorage is implemented - whether we were using Akka Distributed Data or another type of storage should not have any specific impact of them.
Selecting the correct node for execution
Each node is capable of communicating with a specific set of acquiring banks. In our example, this is static and happens via configuration, by assigning specific roles to specific nodes:
| |
The Executor introspects the roles of the node it runs on to be able to make a decision of whether an order is executable:
| |
Order flow
To summarize how a successful order flows through our actor system, a picture will be worth a thousand words:
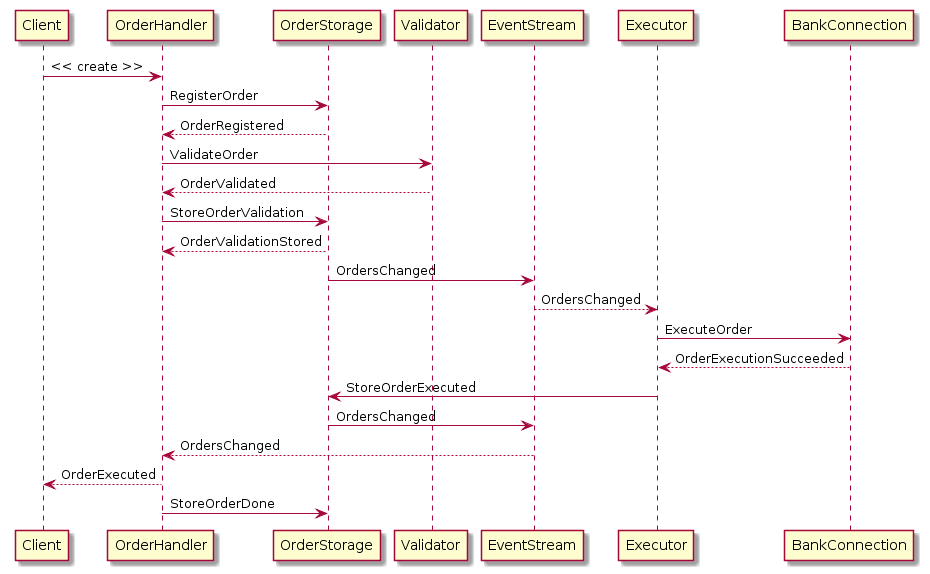
Performance optimizations
There are a few things that we haven’t done yet and that would be a mortal sin haunting our nights, every night, if we were to leave them as-is in a production system:
- defining serializers for our custom data types
- implementing delta-CRDTs to avoid sending full state for updates
- deleting
Doneorders
Let’s discuss those for a bit.
Serialization
When defining our custom data types, it is important to also take care of the serialization aspect - by default, Java serialization will be active, and this is hardly performant at all. Serialization for custom data types is implemented using protocol buffers as described in the Akka Documentation.
Delta-CRDTs
In our example, the Order class is rather simple but could potentially be more complex in reality. As we saw previously, only a small part of the StoredOrder will be subject to change, the rest of the data being immutable. Rather than having to replicate the entirety of the data type every time, it would be much better to only synchronize those bits that have indeed be subjected to a change.
This can be achived by implementing the DeltaReplicatedData type rather than the RepicatedData type.
Deleting Done orders
Once an order has been processed, there is little value for it to still be kept around in our orders ORMap. In principle, this just means removing the key from the map in the modify function. In practice, since we do use an observed-remove map, it means that in the case of a conflicting change (one node removes the order, while another one adds / updates it), the add operation will win. Therefore we need to make sure to additionally prune non-removed Done entries from time to time, should such a concurrent update take place.
Conclusion
In this article we have introduced the example of a reactive payment processor and looked at how to use Akka Distributed Data in order to achieve master-to-master replication. We have implemented our own ReplicatedData types and used them in combination with one of the existing distributed data types provided by Akka.
Whilst the incoming orders are now being replicated, there are a few things that aren’t quite right:
- there is no replication mechanism for the
OrderHandler- if a node was to crash, all orders currently being processed would stay in limbo and the client would not get a response - we don’t store anything in a durable storage, which would be quite crazy in real life!
In the next articles of this series, we will check if our design can be evolved to withstand failure in the face of node outage. Stay tuned!