Tour of Akka Typed: Cluster Singleton and Routers
Contents
In part 5 of this series, we started to scale the application from a local one to a clustered one by introducing Cluster Sharding. In this article, we will continue our effort to scale the payment processor out and make it resilient through the use of Cluster Singletons and Cluster-Aware Routers.
Before we get started, here’s a quick reminder of what we’ve seen so far: in the first part we had a look at the the raison d’être of Akka Typed and what advantages it has over the classic, untyped API. In the second part we introduced the concepts of message adapters, the ask pattern and actor discovery. In the third part, we covered one of the core concepts of Actor systems: supervision and failure recovery. In the fourth part, we covered one of the most popular use-cases for Akka: event sourcing. Finally, as mentioned before, in the fifth part we started scaling out by making use of cluster sharding.
As a reminder, this is where we want to get to:
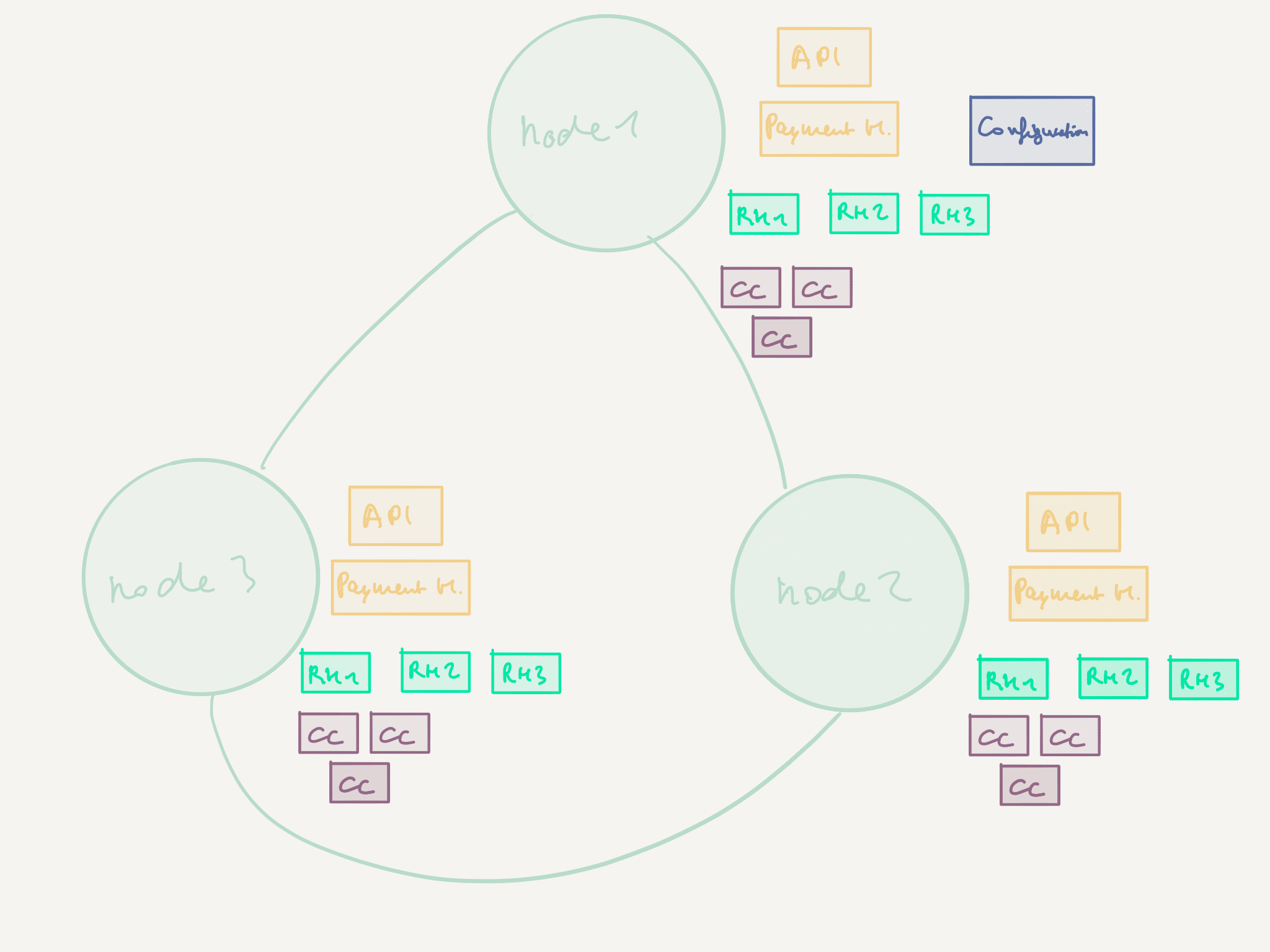
We started to distribute the typed payment processor on many nodes using Akka Cluster in the previous article, but are not finished yet. There are two things we need to still be taking care of:
- make sure that there is only one
Configurationactor in the cluster - or else we’d be risking to run multiple versions of this persistent actor at the same time, which is a big no-go - scale out the
CreditCardProcessoractors in order to increase throughput (by having many of them) and availability (by distributing them on several nodes)
Let’s get started with deploying the Configuration actor as a so-called Cluster Singleton.
Cluster Singleton

The Cluster Singleton feature of Akka Cluster takes care of managing the deployment of an actor in the cluster so that there’s only one instance active at all times. In order to do so, it:
- runs the singleton actor on the oldest node of the cluster
- restarts the actor on another node if the oldest node becomes unavailable
- takes care of buffering messages so long as there is no instance of the cluster singleton running
So what does it take to make use of this feature? With the new Akka Typed API, it is rather straightforward. Previously, we were just starting the configuration actor as a child of the PaymentProcessorguardian:
| |
In order to make use of cluster sharding, we only need to use the ClusterShardingextension, like so:
| |
If you are familiar with the Classic version, you’ll appreciate how much simpler things got - there’s no more need to configure a separate ClusterSingletonManagerand ClusterSingletonProxy, Akka takes care of this. The returned ActorRef[M]is the one you can use in order to send messages to the singleton, and should you not have one at disposal, it is okay to run the initmethod multiple times.
Note that you should be careful to not make too extensive use of cluster singletons in your system - they are, after all, prone to becoming a bottleneck (as there’s only one of them). Make sure you read the documentation to be aware of the trade-offs you are making.
Cluster Aware Routers
There’s one last component in our system that needs some attention with the move to a clustered environment: the CreditCardProcessor. There are two issues with it:
- it will become a bottleneck as there is only one instance of it running per cluster node
- it is backed by a persistent storage implementation that is started on each node, yet uses Akka persistence in the background with the same persistent identifier, which is a big no-go
As part of this article, we’ll fix both these issues but leave room for optimization for the second issue (and thus, room for one article on the topic).
Let’s get started by increasing the amount of CreditCardProcessor-s available in our cluster. Up until now, we only had created one instance of a processor per node. Let’s change this a bit and start 10 of them per node in the PaymentProcessorguardian:
| |
Note that we are still using a custom supervision strategy that will restart the CreditCardProcessoractors (with backoff) instead of stopping them - more on this later.
In the second article of this series, we have setup the CreditCardProcessorto register itself with the Receptionist. This is going to be quite useful now as we’ll leverage the fact that the Receptionistis cluster-aware. Instead of looking up credit card processor’s individually in PaymentHandling using the ServiceKey, we’ll leave this to a new group router which we’ll pass to the sharded PaymentRequestHandler-s (as they are the ones that need to interact with the processors).
| |
And that’s pretty much all we need to create a new router which we can then pass to the PaymentRequestHandlerinstead of the raw Listingreturned by the receptionist. Note that the router doesn’t supervise the CreditCardProcessor routees in any way, which is where our custom supervision comes in to make sure that the 10 instances keep alive over time in case of crash.
Finally, we need to make sure that we don’t create multiple instance of the CreditCardStorageimplementation. In this article and as a first solution, we will just do so by deploying it as a cluster singleton - but this part is left to the reader (or you can always check the sources that go with this article).
And in the next article of this series, we’ll improve the credit card storage by looking into the Typed version of Distributed Data. Stay tuned!
Concept comparison table
As usual in this series, here’s an attempt at comparing concepts in Akka Classic and Akka Typed (see also the official learning guide):
| Akka Classic | Akka Typed |
|---|---|
ClusterSingletonManagerand ClusterSingltonProxy | ClusterSingleton(system).init(...) |
| Cluster Aware Pool Routers | - |
| Cluster Aware Group Routers | Register routees to the Receptionistwith their service key and then get a group router using the service key with Routers.group(CreditCardProcessor.Keey) |