10000 nodes and beyond with Akka Cluster and Rapid
Contents
Update: there’s a podcast episode about this
The year is 2021. As the world is still deeply affected by the COVID-19 pandemic, the United Nations have decided that in order to prevent the same scenario of ever happening again, there should be a worldwide, real-time contact-tracing system in place capable of tracking every human being on the planet. Everyone is now equipped with a small, pebble-like device. If a person you have been in contact with is confirmed to carry a new kind of virus for which there is no remedy, the device starts glowing in red. Each device reports the anonymized contact information to one global backend system capable of handling this type of massive scale.
Two months ago when I first started working on this project, the paragraph above would have sounded to me like an unlikely future taken straight out of a dystopian science-fiction book. Fast-forward to today and I really have to wonder whether this scenario might not actually happen one day.
In the beginning of 2018 I started to get more and more interested in the building blocks necessary to create clusters. At the foundation of clustered systems are so-called membership protocols. The job of a membership protocol is to keep clustered applications up-to-date with the list of nodes that are part of the cluster, allowing all the individual nodes to act as one system.
Up until November 2018, I considered the SWIM failure detector and membership protocol together with Hashicorp’s Lifeguard extensions to be the state-of-the art in this domain. Then the paper Stable and Consistent Membership at Scale with Rapid (L. Suresh et al., 2018) struck my eye and I’ve been itching to try it out since then. I finally decided to make the time to try it out (that is to say integrating it with Akka Cluster) at the end of February. What I first thought would take a couple of weeks at most turned out to take two months. This is in big part because because I had set the goal to create a 10000 node cluster on cheap AWS EC2 instances - I didn’t want to settle for 5000 nodes because that was too close to the already existing 2400 node Akka cluster. Coupled with the COVID-19 outbreak and the resulting change of lifestyle, these have been a very strange and exhausting, yet interesting, two months.
The rest of this article is structured as follows:
- a bit of theory: how Akka Cluster’s membership layer works and how Rapid works
- the journey to 10000 and beyond: what it took to get the protocol to scale on AWS EC2 t3.micro instances
- lessons learned and future work
Akka’s membership service
Akka Cluster was created in 2013. For reference, here’s Jonas Boner’s talk about The Road to Akka Cluster, and beyond which shows what motivated the design of the system.
The following is a summary of how the membership service works.
Dissemination
Propagating membership information is achieved via random biased push-pull gossip. At each tick of the clock (1 second by default) each node:
- picks a node at random (well, almost) to send it a gossip message containing its current view of the cluster
- the pick is biased so that nodes that aren’t known to have seen the latest version of the gossip are picked first
- if the recipient of a gossip message notices that the sender is out-of-date, or if the gossip messages conflict and need to be combined (more on this below), the recipient of the gossip will send back the new version. This mechanism is known as push-pull gossip.
Consensus
Agreeing on who is part of the membership group is achieved using by combining two mechanisms: strong eventual consistency and leader-based decisions.
- Gossip messages carry a vector clock (not to be confused with a version vector) which are used to detect conflicting versions and merge the state of the world as a result. In order to be able to remember removed nodes, tombstones are used, a technique commonly used in Conflict-Free Replicated Data Types (or CRDTs). So essentially, Akka’s Gossip message is a specialized CRDT.
- The leader of the cluster is designed by convention (as opposed to elections as in Paxos or Raft) - it is the first member by network address with the correct status. It carries out membership-related decisions such as allowing a node in the membership list or letting it leave.
- The membership state is said to have converged when all members have seen the latest version of the gossip. Some leader actions are only carried out upon convergence, such as promoting joining members to full-fledged members of the group.
When one or more nodes are suspected of having failed by the failure detector (see below), a decision has to be made as to how to progress. Because of the FLP impossibility result, the leader cannot make progress and the failing node(s) either have to be removed (downed) manually or automatically via a downing provider. It is the downing provider that needs to take into account special scenarios such as network partitions or multi-way (e.g. 3-way) network partitions.
Failure detection
Detecting failed nodes in Akka Cluster is achieved by having each node maintaining a ring of subjects (i.e. monitored nodes), 9 by default since Akka 2.6 (5 in previous versions). Edge failure detection (that is to say, failure detection between two nodes) is implemented by the Phi Accrual Failure Detector. Failure of an edge will cause the reachability part of the membership state of a node to be updated and gossiped about.
Joining the cluster
New nodes can join the cluster by contacting a seed node. Seed nodes are ordinary nodes with the exception that they are well-known (e.g. exposed via configuration). Nodes are initially admitted in the membership group as weakly up and then promoted to being (strongly) up by the leader once convergence is reached. The weakly up state was introduced so as to allow joining nodes to already perform some tasks that do not require the entirety of the membership group to know about them while the cluster state converges via gossip.
The Rapid membership service
Rapid is designed around the central idea that a scalable membership service needs to have high confidence in failures before acting on them and that membership change decisions affecting multiple nodes should be grouped as opposed to happen on a per-case basis.
Dissemination
Dissemination of membership information in Rapid happens via broadcast. In the version of Rapid used in the paper, the broadcast is based on gossip that takes advantage of the expander graph topology according to which nodes are organized in Rapid. These types of graphs have strong connectivity properties and it is possible to know how many times a gossip message needs to be relayed before it has traveled the entire graph.
There are two types of messages that are disseminated in a Rapid cluster:
- alert messages about an edge (from node A to node B), either UP or DOWN. Those alert messages are batched together if one node emits more than one alert within a defined batching window)
- consensus messages that carry a view change proposal, that is to say the list of members affected by a change.
Each of these messages carries a configuration ID with it that denotes the current version of the membership view (more on this below).
Consensus
Rapid adheres to the virtual synchrony approach. In Rapid, nodes agree on view change proposals. Each proposal leads to a new (immutable) configuration containing a list of members. Each new configuration represents a new system (a view on the membership list). The membership change proposals are based on failure detection and joining nodes, both these things being grouped together by the multi-node cut detection mechanism explained later.
Consensus is first attempted via Fast Paxos by counting the votes for each view change proposal at the recipients. If a quorum is reached, a new configuration is adopted which includes a new expander graph topology. If consensus can’t be reached this way after a certain amount of time, full Paxos is used as a fallback protocol (that is, it could also be Raft or another consensus protocol with a modified rule for the coordinator to pick values).
The key insight in the Rapid paper is that the cut-detection achieves almost-everywhere agreement with high probability, which makes it so that the Fast Paxos round can be completed in a single messaging round. I suggest reading the paper to get a more in-depth understanding of this.
Failure detection
Nodes in Rapid are arranged according to an expander graph with strong connectivity properties. Each node has K observers (that monitor it) and K subjects (which it monitors). If the edge failure detector of an observer node suspects a subject of having failed, it will broadcast an alert to all members of the current configuration.
Each node has a multi-node cut detector that acts as a high-fidelity filter for edge alerts. This filter defines a low (L) and high (H) watermark and counts the alerts (of the same type) for each subject. As soon as:
- there is one node for which there are more than H alerts
- there are no more nodes for which the count of alerts is between L and H
a new proposal is passed on to the consensus mechanism.

One particularity of Rapid is that the edge failure detector is pluggable by design (and in the implementation), which is quite nice when integrating it with existing systems such as Akka.
Joining the cluster
New nodes can join the cluster by contacting a seed node. Seed nodes are ordinary nodes with the exception that they are well-known (e.g. exposed via configuration). The join protocol has two phases:
- first, a joining node gets a reply from the seed node containing the addresses of their observer nodes - if it is currently safe to join the cluster, i.e. if there’s no view change in progress
- the joining node then sends a second join request to all of its observers which in turn each broadcast an edge alert of type UP to the rest of the members. The multi-node cut detector then processes those alerts and a new consensus round is started
What Rapid brings to the table
One of the motivations for Rapid was to be faster at scale than existing consensus protocols. The Rapid paper shows that Rapid can form a 2000 node cluster 2-5.8 times faster than Memberlist (Hashicorp’s Lifeguard implementation) and Zookeeper.
One of the problems with membership services that rely entirely on random gossip is that random gossip leads to higher tail latencies for convergence. This is because messages in larger clusters can go round and round and bump into conflicting versions, especially in the presence of unstable nodes. In the 2400 node Akka Cluster experiment, 1500 nodes were initially added in batches of 20 every 3 minutes. In contrast, I’m able to bootstrap a 2000 node cluster with Akka/Rapid in about 15 seconds (the graph below was taken before protocol modification / performance optimizations and with one of the early, flaky and buggy messaging implementations):
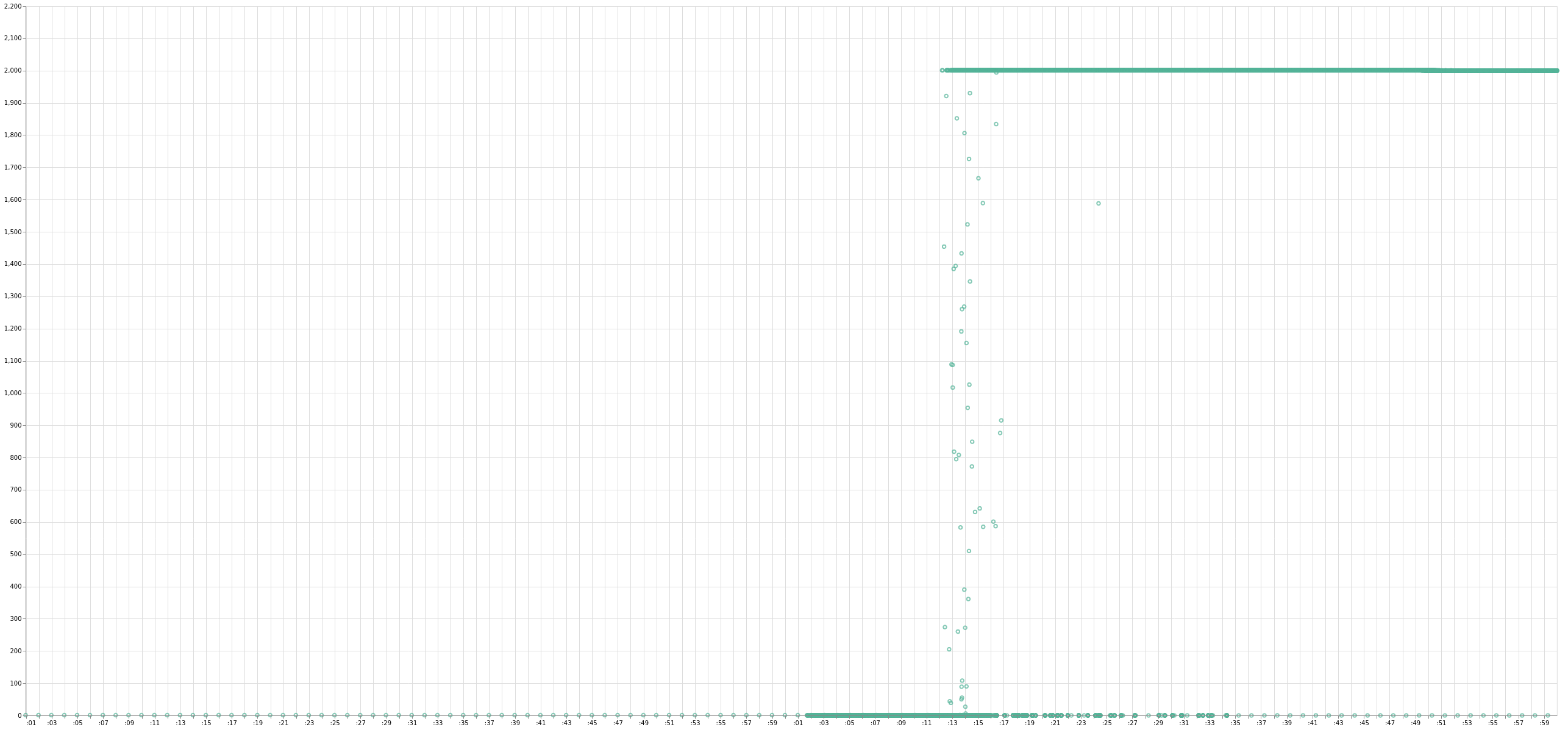
Another one of the big contrasts that in my opinion sets Rapid ahead of other membership protocols is the strong stability provided by the multi-node cut detector. A flaky node can be quite problematic in protocols where the failure detection mechanism doesn’t provide this type of confidence.
Lastly, mixing system-specific reconfiguration and normal membership operation is not optimal as it makes failure scenarios harder to handle. Rapid focuses on being a membership protocol and leaves it up to the application layer to design reconfiguration protocols on top of this input.
With all of this enthusiasm about Rapid, I ventured into integrating it with Akka and launching a 10000 cluster node. Let’s see how that went.
Notes from the road
21.02.2020
The basic integration works locally, tested it with up to 9 nodes bootstrapped by hand in the terminal. Integrating the Java Rapid implementation with Akka Cluster was easier than I thought. This is clearly a proof of concept, I simply ripped everything out of the ClusterDaemon, bootstrapped the cluster via Rapid and converted Rapid’s view-change events into Akka’s Gossip messages, making it look to Akka as if the changes it sees come through the gossip protocol. There are likely edge cases left, but this isn’t meant as a production ready integration at this point.
Messaging is implemented via Artery TCP. Still using Rapid’s ping-pong edge failure detector, seems to be enough.
27.02.2020
Got the operational setup in place. Since I’m not going to bootstrap thousands of VMs via the EC2 UI console, I resolved to using Terraform like for the accrual failure detector experiment. IntelliJ support for Terraform syntax has gone a long way since then. I guess people are going to ask why I didn’t subject to our new borg overloads (can’t write it like this, everyone is rooting for k8s, the special forces are going to get me) choose to use kubernetes / containers. This is a very conscious choice:
- containers and container orchestration engines have their own networking implementation and model which I have absolutely no desire to add to the mix in this experiment. Now, EC2 instance networking is also rather opaque, but I’d argue that there are much less surprises when it comes to its behavior. Seeing what others write about network stalls on kubernetes shows that there clearly is one more layer of complexity involved and I don’t want this complexity for this type of experiment at the moment, not until it works, anyway.
- I have the feeling that I’ll need to tune kernel parameters to get to 10000 nodes. This is not going to be easy or possible when using managed container orchestration platforms.
Just as 3 years ago, the VMs are bootstrapped with a custom AMI also built by the same Terraform module. Call me old-fashioned, but at least I have total control over the environment.
The initial scaffold of the experimental setup is in place. Nothing fancy, probably won’t need to be more complex than this. The coordination node bootstraps a HTTP server with a simple API, all other nodes first register with it and poll it regularly to see if they should start. If they get a green light, wait until the next minute to start at the same time. Time is kept in sync via the AWS time sync service, also needed to get logs to align. Using Papertrail for the logs just like 3 years ago, probably will be sufficient. Just need to figure out a way to turn the member counts of each node into a plot.
Also fine-tuned the integration and integrated Akka’s Phi Accrual FD. After e-mailing with Lalith, added a leaveGracefully method to the Rapid implementation to get rid of the errors in the logs when shutting down a JVM gracefully. Seems to work.
This corona virus thing is taking over all the headlines.
02.03.2020
Replaced Papertrail with elastic cloud after talking with Peter. There’s a 14 day trial, that’s certainly going to be long enough to run the 10000 node experiment.
Also got Vega visualization to work, Peter sent me a link detailing that. Good to be able to plot the real value (and not an average / median / min / max aggregation).
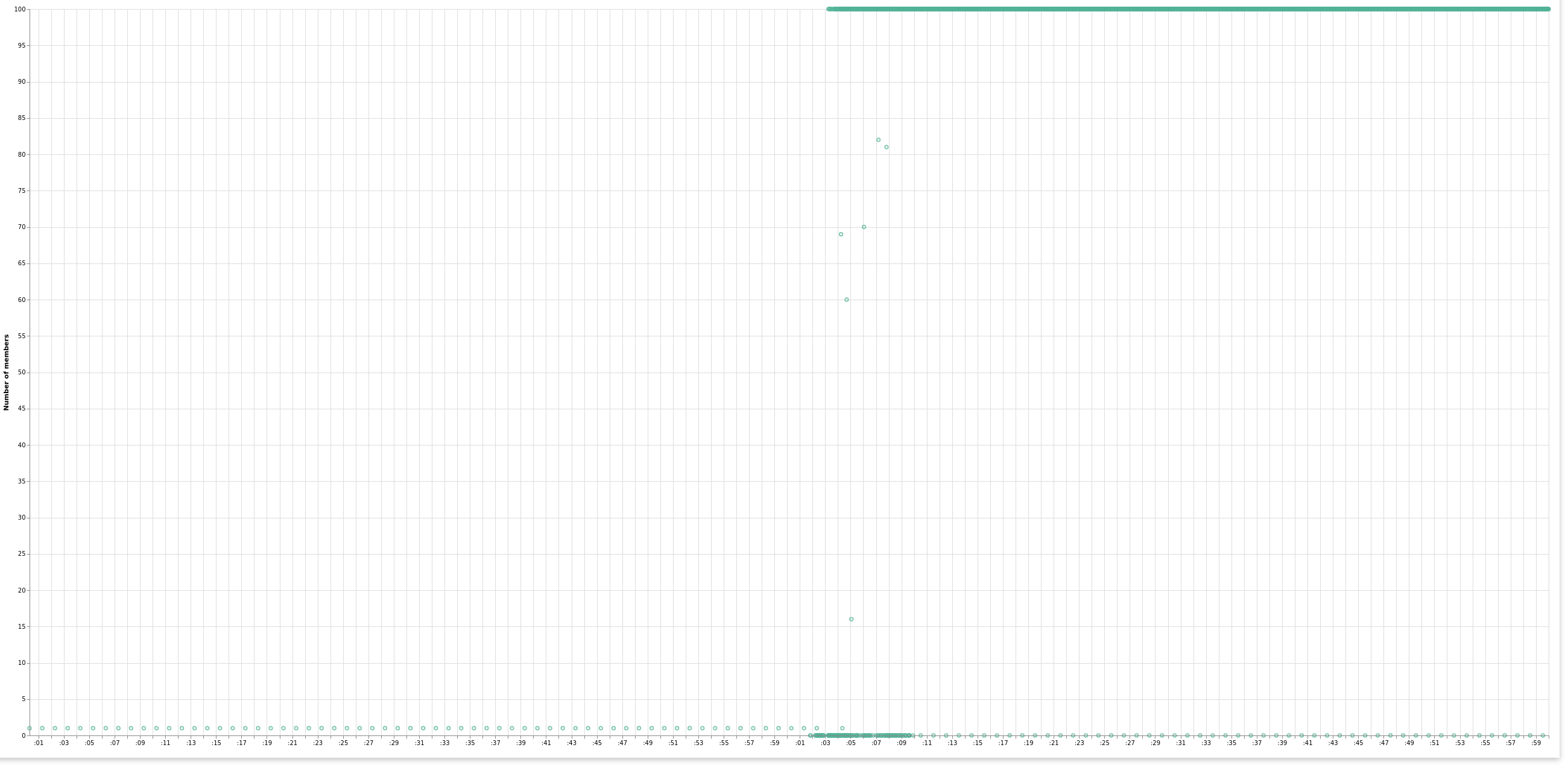
04.03.2020
Flight to Nice, to see my parents with the kids. Not sure how much I’ll get done there. Checked with the NCE airport, there are no checks for travelers coming from AT. Seems to be crazy to check anyway, they’re not going to start checking everyone at the airport, that can’t scale.
06.03.2020
Found a bug that kept me from running a 1000 nodes cluster - only 875 nodes find each other, no progress after that. Turns out there was a bug in how Rapid handles a race condition in the phase 2 of the join protocol, the metadata was not sent back to the late joiner. Using Rapid metadata to carry Akka Cluster’s node UID. Rapid also has a UID concept, a better integration would use that one in both places or something like that.
Now stuck at 1024 nodes. Why 1024?
09.03.2020
AWS autoscaling groups are expensive! Cloudwatch costs are almost as high as EC2 costs, and they’re not much faster than doing this via RunInstances. Back to launching EC2 instances directly.
Good thing we flew back to Vienna yesterday, the Corona thing is starting to look pretty serious.
Still stuck at 1024 nodes.
10.03.2020
Finally figured out what the 1024 limit was. Turns out this was the max size of the ARP table cache. Since all the EC2 instances need to be in the same AZ (cross-AZ latency is not really an option, not with t3.micro networking), they all end up in the same subnet. The following in the template node setup script does the trick:
| |
2000 nodes work without problem. Asked AWS support to increase the RunInstances API rate limit to 1000 / second instead of 5 / second, let’s see what they’ll say.
13.03.2020
Elastic Cloud trial runs out next monday so attempted a 10000 node run, only to get stuck at running 4090 nodes after an hour or so of watching nodes being bootstrapped. Subnets have a limit of 4091 IPs and Terraform / the AWS API (not sure which) doesn’t automatically launch new instances on another subnet when the first one is full, this has to be specified by hand. Now splitting the instances across 3 subnets.
Also the cluster size didn’t get past 2665 because of the message size of join phase 2 responses: Failed to serialize oversized message [com.vrg.rapid.pb.RapidResponse]. Should’ve seen this coming.
This is taking longer than I thought.
16.03.2020
They closed the borders. And the daycares. No idea how this will work out. Reading the news is very distracting.
Stuck at 2300-something nodes, sometimes 2600-somthing. Something is off somewhere but I can’t put my finger on it. Suspect that it is the CPU / memory of the t3.micro instances but can’t be sure yet.
18.03.2020
Started profiling the JVMs with async-profiler. A few observations:
- they definitely have different performance. For the same batch, running the same code, large differences in execution times. But okay, t3.micro isn’t supposed to be reliable in that way, they clearly state this in the documentation.
- I ran into a micro-partition while profiling nodes at random. SSH into the node works, SSH / ping / netcat / whatever from that node to other nodes doesn’t and vice-versa. So that node was completely isolated from the others, but not from the outside. Partition was resolved after 5 minutes. This type of failures is going to be fun to work with.
19.03.2020
With a cluster reaching 2000-ish, 40% of CPU time spent on ArrayList.contains
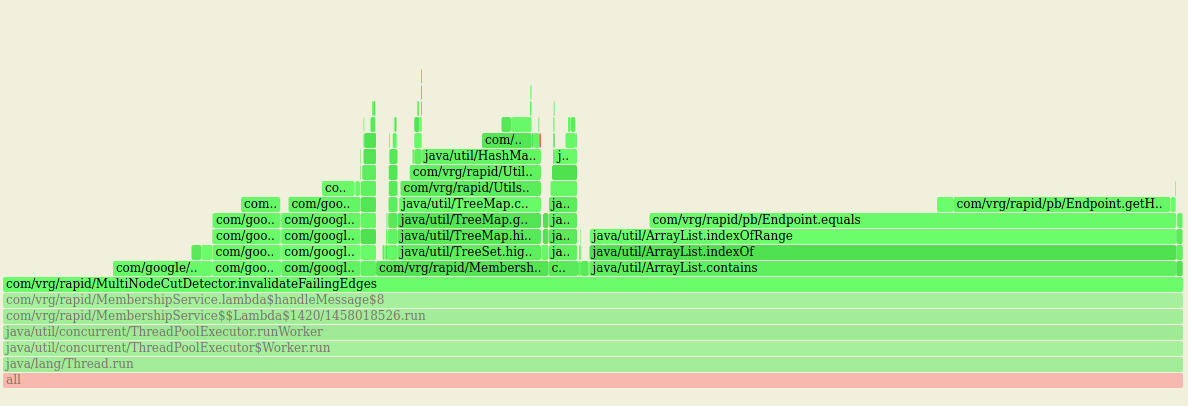
Also a lot of time spent on TreeSet.contains and on comparing node addresses, needed to implement the expander graph:
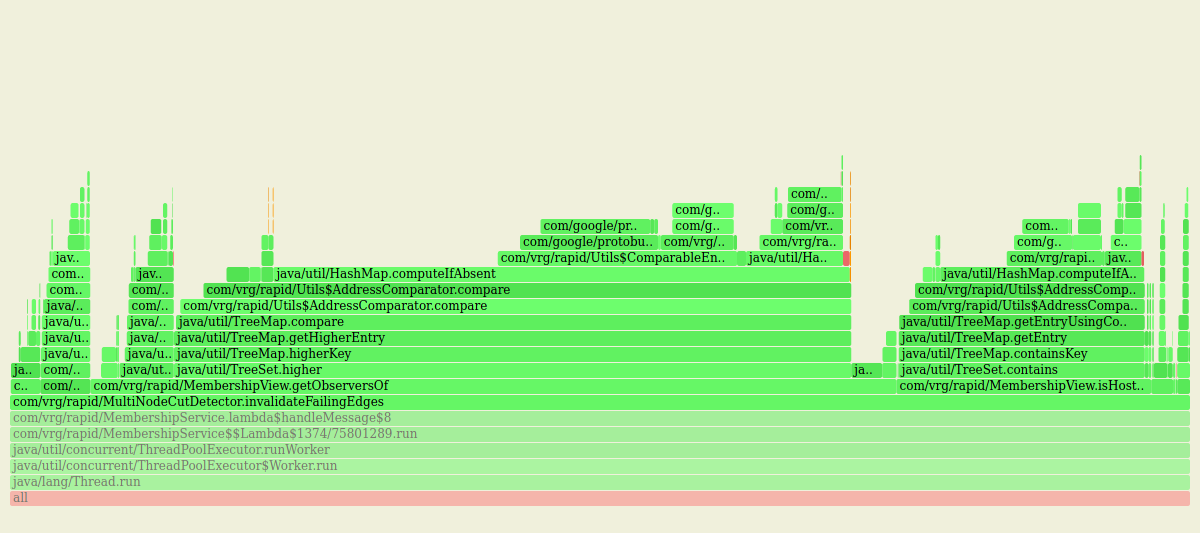
Working around this by caching computed observers for the moment.
20.03.2020
Submitted a PR for the performance optimizations. Also made Rapid’s alert batching window configurable, the default of 100ms is too small at this scale.
Working shifts with my wife, morning shift and afternoon shift. Adding evening shift now and then when not bringing kids to bed. This is starting to get exhausting. Hope it is going to be over soon.
23.03.2020
AWS accepted my request to start 1000 instances / second. This! Is! Sparta!
24.03.2020
Another week, not much progress. Kids aren’t sleeping well, the whole Corona situation is clearly not helping and they can sense our own uncertainty and exhaustion. It’s hard to think on little sleep, but I tried to go back to first principles nonetheless this afternoon.
There are 3 main factors limiting scaling of the protocol and the experiment:
- the amount of links each node needs to establish with other nodes when broadcasting edge alerts
- the amount of messages sent
- the time it takes a node to process incoming messages
Going to spend more time on 3, something tells me there’s still room for improvement - address comparison shouldn’t be taking so much CPU cycles.
25.03.2020
I’m going to introduce a simple tree hierarchy to do the broadcasting part, since there’s no way that the t3.micro instances are going to be able to establish that many connections. Something very simple: more powerful instances taking care of broadcasting messages on behalf of the smaller instances. Smaller instances just pick one at random each turn. That should be enough.
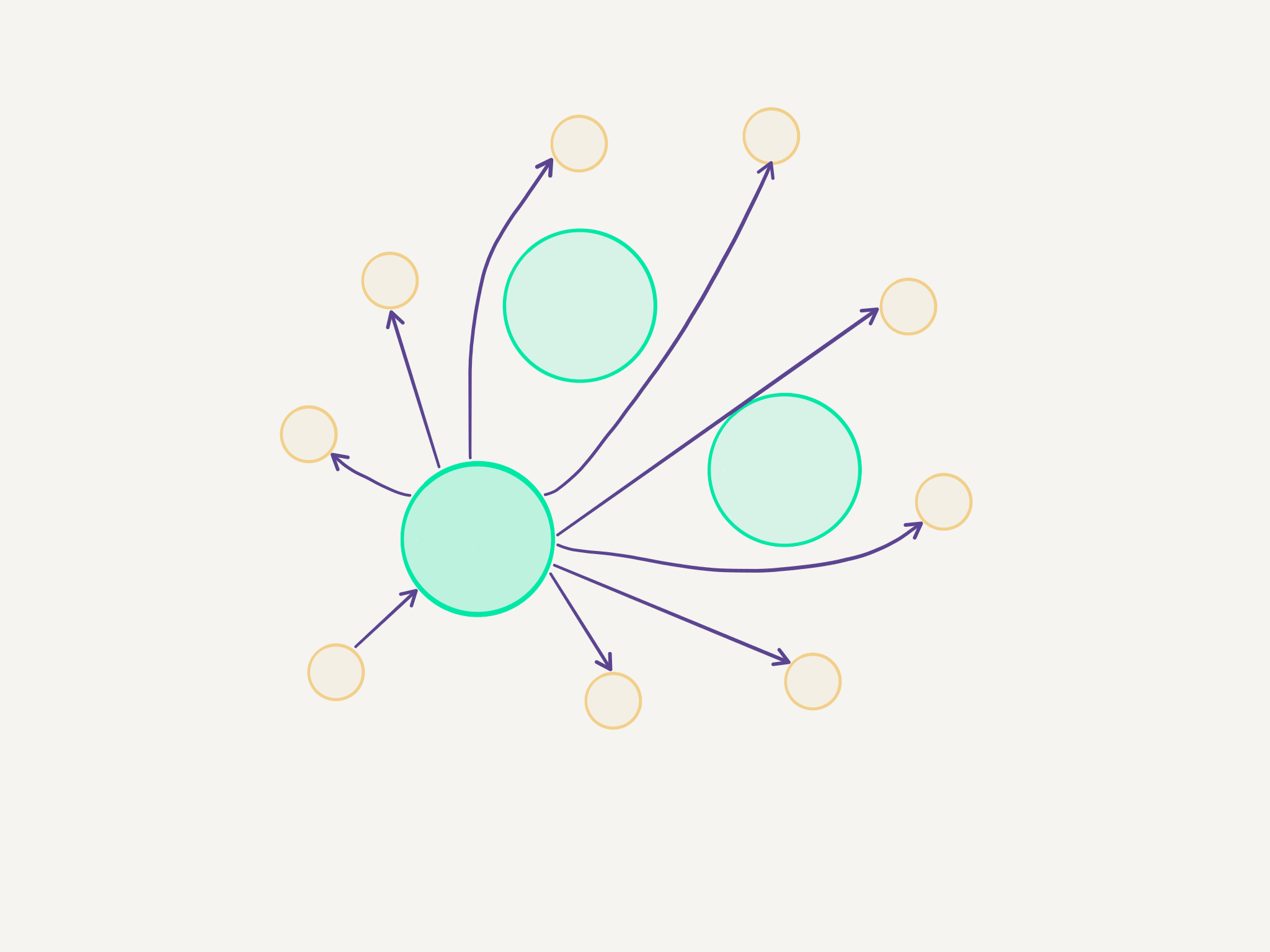
26.03.2020
Found a bug in Artery. Temporary actor references created when using the ask pattern are advertised in the compression table. The t3.micro’s were pausing every minute when receiving that table, that’s how I noticed.
Submitted a PR.
It looks like this lockdown is going to take at least another month or so. Cancelled Netflix since there’s no more time to watch.
27.03.2020
Another week, no success. Ran a 10000 node experiment, what a fiasco! After waiting for AWS for two hours to launch the 10000 nodes (something is off with Terraform), only got to a cluster of size 1000. I shouldn’t be running these experiments when tired.
Need to look into what Terraform is doing with RunInstances.
As a side-effect of the confinement and me being around so much, the kids are starting to talk more and more french. At least something.
30.03.2020
It’s always the strings. Or ByteStrings, in this case. Got rid of the roundtrip ByteString <-> UTF-8 encoded string in the Rapid implementation for hostnames, resulting in 10% CPU performance improvement and 20% less memory allocation:




Email exchange with Lalith, going to simplify the join protocol which should drastically reduce the amount of messages exchanged when new nodes join.
01.04.2020
Wearing masks in public (supermarkets, public transports) is mandatory.
Nobody feels like joking today on the internet.
Observed a one-way partition for one of the nodes: possible to SSH into it, other nodes not reachable, but the other nodes can reach it. Resolved shortly thereafter.
02.04.2020
Implemented a simplification of Rapid’s join protocol. Instead of being split in two phases and having the joiners talking to K observers in the second round, the gateway node now broadcasts alerts on behalf of the observers.
This allows to leverage alert batching: by extending the batching window to a few seconds, many joiners get batched into just a few batched alert messages and drastically reduce the amount of traffic when new nodes join.
This should help a lot!
03.04.2020
It didn’t help a lot.
Ran another 10000 node experiment and only got to 3000 nodes.
At least I can run EC2 instances a lot faster now after hacking terraform’s AWS provider which was calling the DescribeInstances API after every RunInstances call for a single node. Go is a very repetitive language.
I’m going to be able to spend all of my money on EC2 so much faster now.
05.04.2020
Had an idea in the shower:
Day 21 of social distancing. The drawings have extended to the bathroom mirror. After a while I realize that the schema of a consistent hashing based broadcasting protocol has a familiar shape. Unsure where this is headed pic.twitter.com/BYEi8HnmIA
— manuel 🦋 @manuelbernhardt (@elmanu) April 5, 2020
I thought that the simple broadcasting mechanism was going to be enough to scale out, but that’s just not true. My very strong suspicion is that the bottleneck is the amount of pair-to-pair connections (coupled with the message load). Even large broadcaster instances aren’t able to sustain that type of message load at scale over so many concurrent connections in such a way that the illusion of multicast required for the protocol to function still holds true.
So the idea is to devise a broadcasting mechanism designed specifically to reduce the amount of connections each broadcaster has to hold.
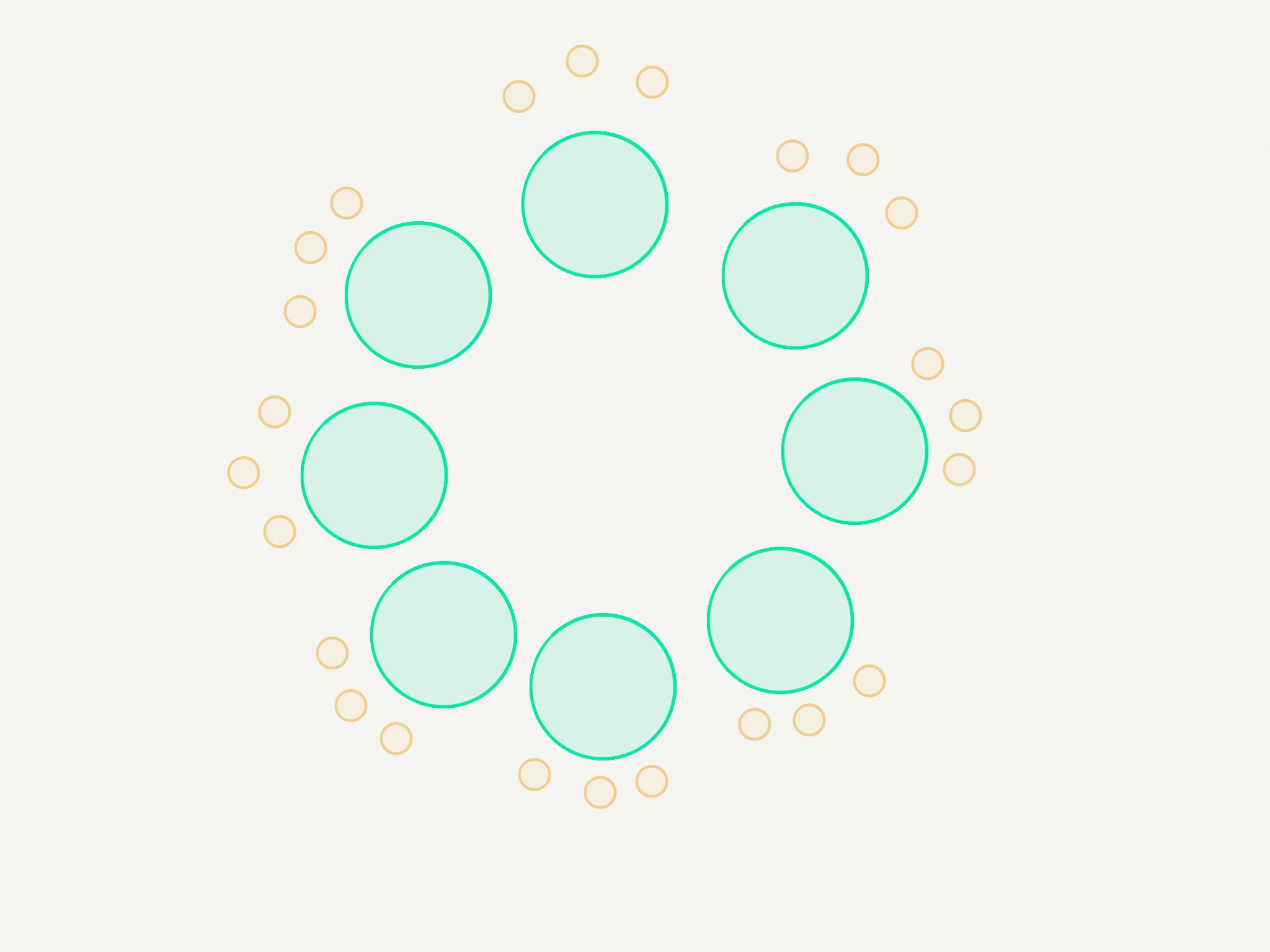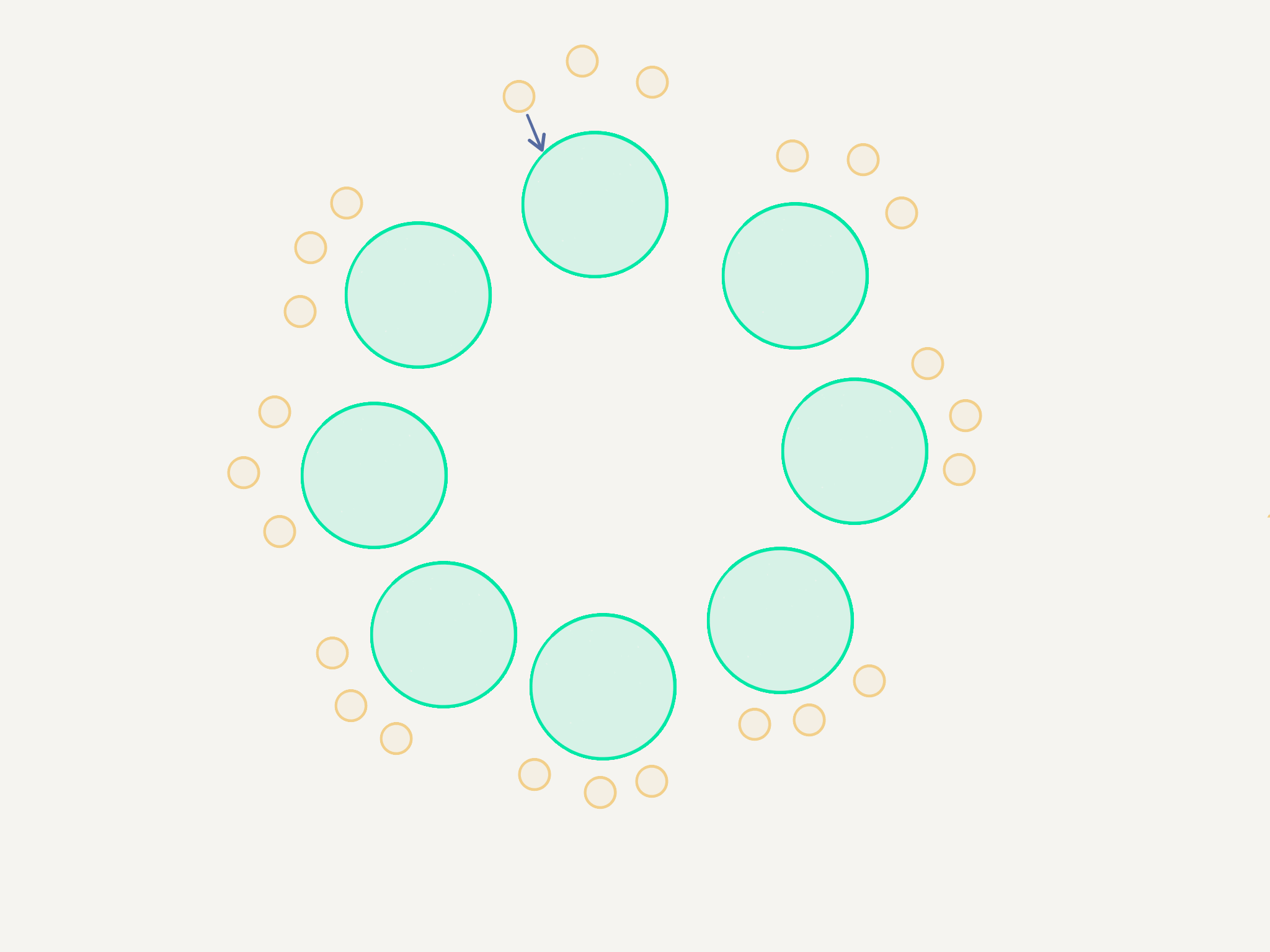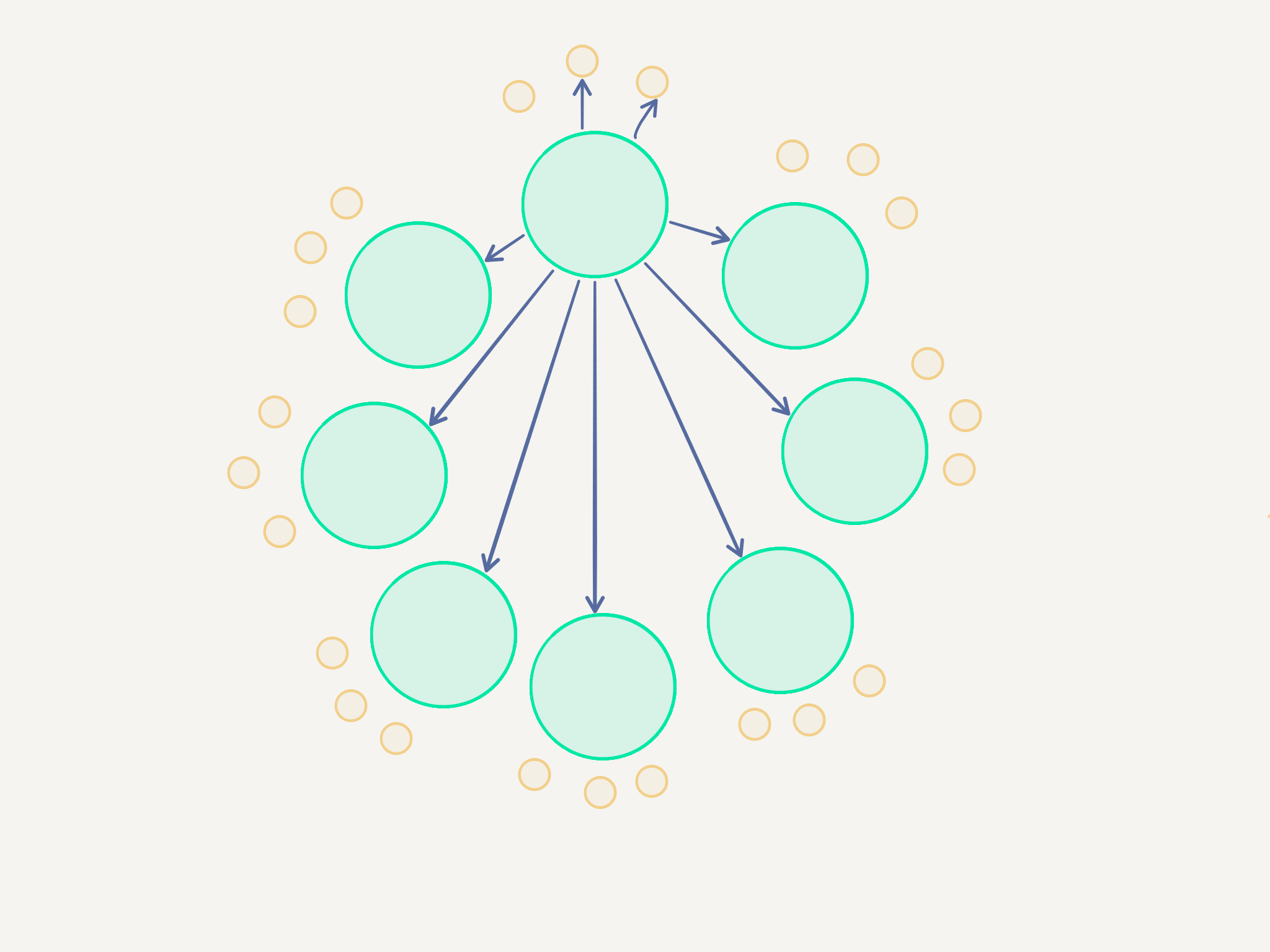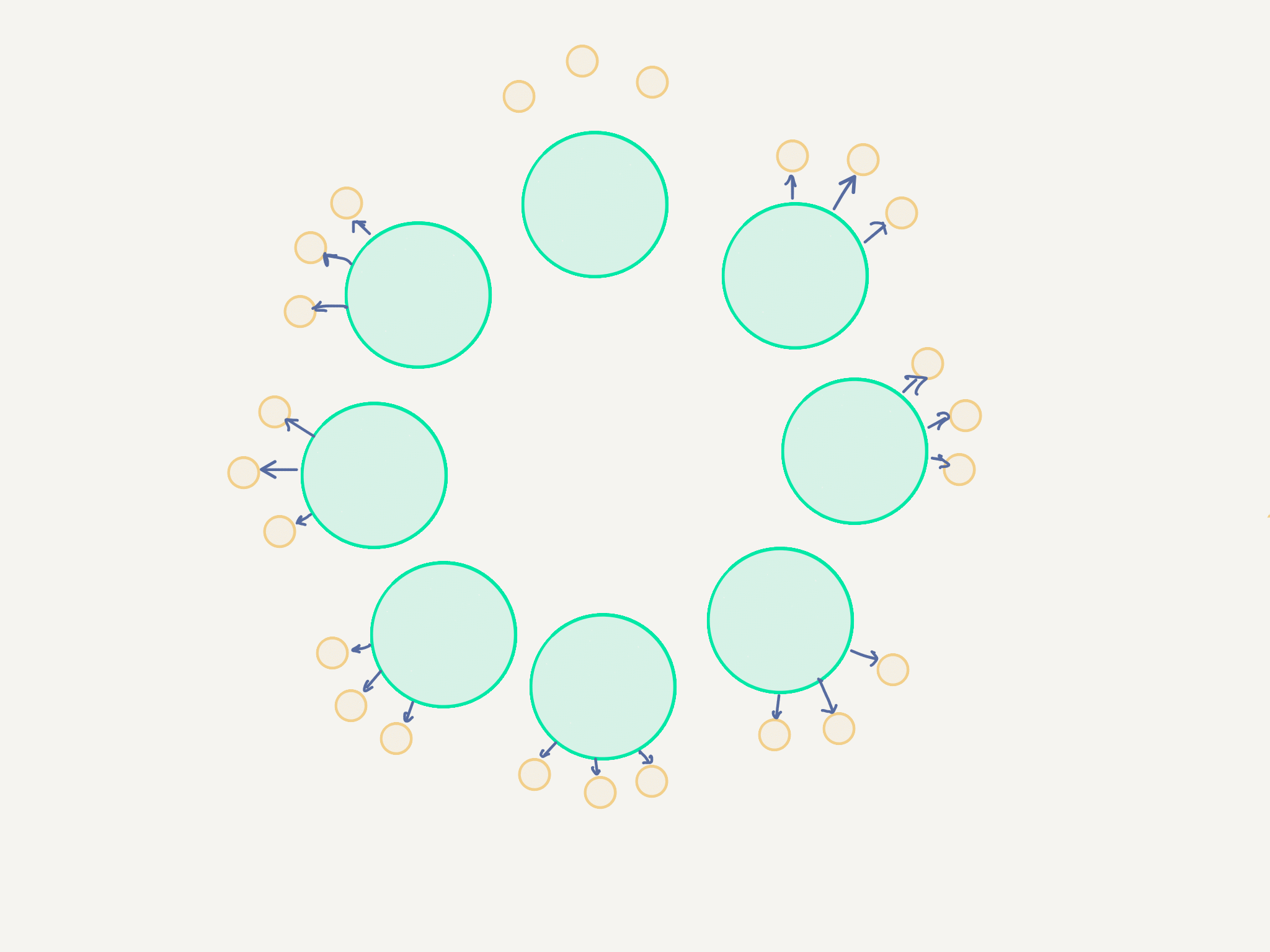
For 10000 nodes this means:
This should be entirely manageable.
06.04.2020
Started implementing the Consistent Hash Broadcaster. Need to think of a better name. Corona Broadcaster too bleak.
07.04.2020
Another 10000 node run, only got to 3000 nodes and the connections still keep on growing beyond the expected ~200 per broadcaster. This doesn’t make sense, there has to be something else going on.
The “simple” experiment coordinator is turning into a monster, Forde’s tenth rule applies. Rewriting it to model at least some of the transitions explicitly.
10.04.2020
I haven’t shaved in days.
I’m reminded of these people writing these “30 things you should do before breakfast” lists. Let them have my kids for just a day and have breakfast with them at 5:30 AM, we’ll see how much they get off their list then.
What makes this entire experiment difficult is that the performance of individual nodes is affected by the size of the cluster as is the size of JOIN responses. Something that still works well for 3000 nodes may turn out to be just very wrong at 6000 nodes. Calculated that they’ll get to 1.39 MB when the cluster reaches 10000 nodes. I could actually send them over to the joining nodes via floppy disk.
Got the maximum response size down to 1 MB by using IP addresses instead of EC2 hostnames.
13.04.2020
Forgot to terminate ~4000 instances over the prolonged week-end after the last experiment (the InstanceTerminator script got rate-limited and failed), which cost me 700$ in EBS fees. @#$%^&*()_+! The total cost of this experiment is now close to 3000$.
At least today I figured out where the mysterious connections come from.
The spanning tree reconfigures itself after each view change. But not in such a way that would make this obvious – that would be too easy. Most nodes are not or only mildly affected, but a small subset of the nodes get a whole new set of subjects and observers, which means 20 new connections per round.
Setting akka.remote.artery.advanced.stop-idle-outbound-after = 20 s to discard old connections did the trick. Now at 7501 nodes.
Going to optimize this and do one final run tomorrow. Going to rewrite the experiment coordination to have the nodes be called back instead of polling the coordination node, which should reduce pressure on that node.
This time it will work.
14.04.2020
It didn’t work. Got to 8502 nodes.
I have to stop, this is getting too expensive. Time to wrap up and write a nice article. It would have been nice to be able to say that I managed to form a 10000 node cluster (it’s a nice, round, number), but this is getting out of hand. Probably this can’t be achieved on t3.micro instances anyway so this is all just a huge waste of time.
This is the grown up thing to do.
20.04.2020
I’m going to try just one last thing.
I think that the t3.small instance performance that is the bottleneck, they probably can’t handle the vote messages in later rounds. Batching together the fast paxos vote messages at the broadcaster level should help.
The broadcasting mechanism used in the Rapid paper is based on a gossip that aggregates votes at each gossip hop. The message carries a bitmap implemented as Map[Proposal, BitSet] where the index in the BitSet represents the index of a node in the member list.
22.04.2020
Implemented the vote batching as part of the Consistent Hash Broadcaster (need to think of a better name) and testing it locally to see if there’s odd behavior at a small scale.
Managing to run up to 200 nodes on the 32 core Thunderbolt machine, giving the nodes 80MB of memory each except for a coordination & seed node and two broadcasters.
Mostly works, but sometimes there are 1-2 nodes with 0 members showing up in the logs even after the rest of the pack has agreed to 200 members. Probably not a big issue.
23.04.2020
Can’t get those 0 member nodes out of my head. They can’t have been kicked out of the member list as otherwise the cluster size would be 198 or 199. So they must have missed the batched votes messages.
I came up with the idea of using an anti-entropy mechanism, a bit like the one in Lifeguard: if a node figures out that it is out of sync, it will ask another node for the latest state. The failure detector probe messages could be used for this by having the observers send the configuration id as payload. If the subject realizes it is out of sync, it would wait for a bit and then take the necessary measures to get back on track.
I implemented the mechanism but with a twist: when a node realizes it is out of sync, and it if is still out of sync after one or two minutes, then it will leave. I think this is going to be the ultimate weapon against the micro-partitions in EC2. This is how I will get to 10000.
This time it just has to work.
24.04.2020 08:19 AM
Failed 10000 node experiment. There was a deadlock at 2103 nodes due to a bug in the implementation – broadcaster nodes trying to apply a view change while still broadcasting the votes from the previous view.
Good thing I can start and stop 10000 instances in under 10 minutes now.
24.04.2020 09:14 AM
No progress past 3092 nodes. Why 3092 nodes? What have 3092 nodes got to do with this all? At least 3042 would have made some sense…
At this point there should be very few messages left flying around, so this can’t be CPU and it can’t be memory. So it has to be protocol-related.
I don’t know why yet, but my intuition tells me that I need to increase the pause between batches of new nodes joining after the coordinator has seen a view change.
Now waiting 25 seconds after a view change has happened at the coordinator node.
24.04.2020 10:37:52
Well, this has been a ride!
Epilogue
I figured what went wrong with the 9:14 AM run. This is a combination of two things:
- nodes that receive enough votes for fast paxos consensus will perform a view change directly, which means that some nodes will have progressed to a new view before others. If a batch of nodes is allowed to join, the members already in the new view will start processing alert messages and start a new consensus round while some nodes are still in the old view. Normally, this would be prevented in a system with virtual synchrony by waiting for the acknowledgment of the transmitted messages, but this isn’t the case here (there is no acknowledgment chain)
- the implementation of the Consistent Hash Broadcaster with batching does not preserve message order
Therefore a “distant” node may see the alert messages from a new batch of joiners before the votes from the previous round – leading it to discard those messages and thus be stuck. This should be rather easy to fix, but I’m not sure yet which one is the better for, now whether it is worth pursuing the Consistent Hash broadcasting over a gossip-style broadcasting.
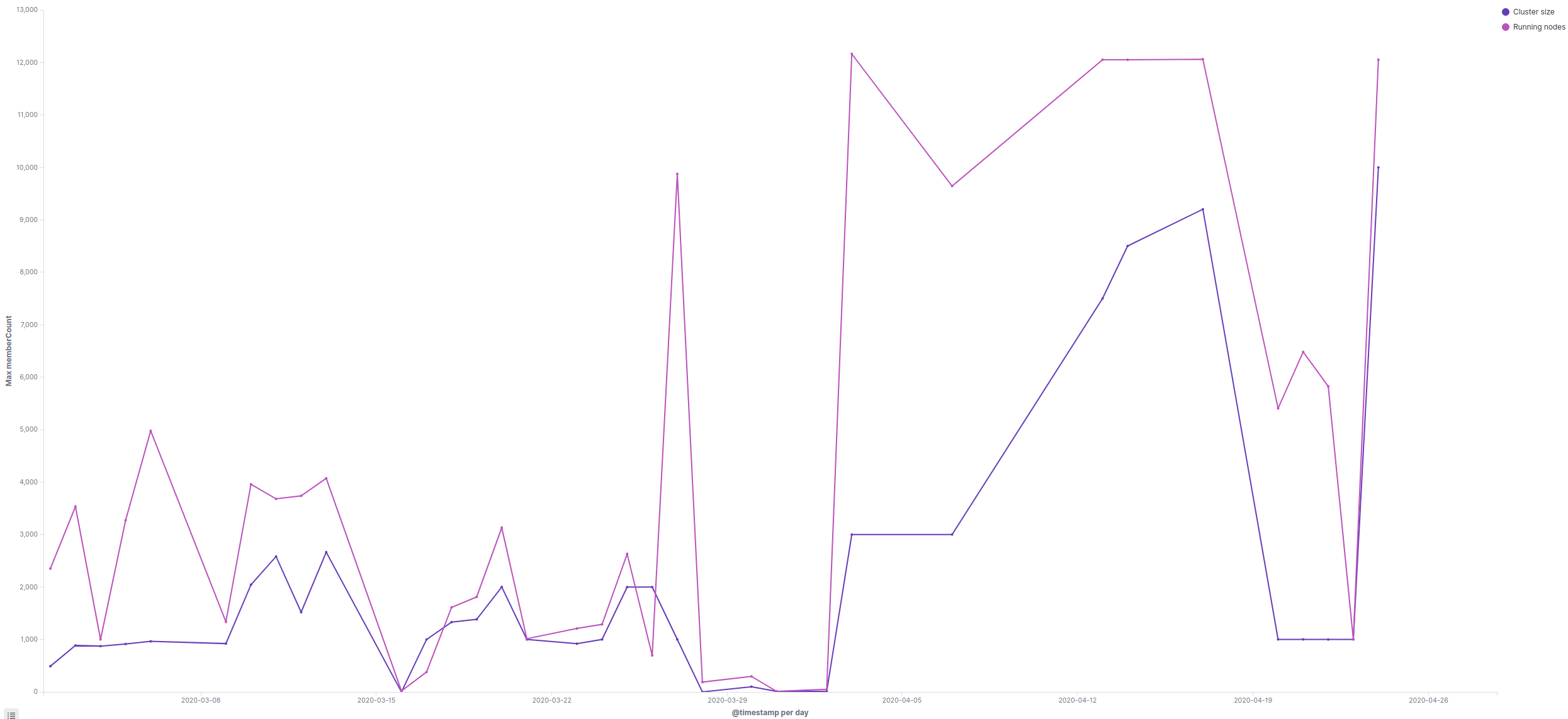
Note that the graph above (and all the other graphs shown in this article) was produced by Kibana. I must say that in hindsight this tool has been extremely useful.
There are a few things that I’d have liked to try, but this time around it really is time for me to stop spending money on EC2 instances. Those would be:
- implement a gossip-based broadcasting mechanism like in the original paper and see how quickly this reacts at that scale
- reduce the failure detection interval and timeout (I set them quite high on purpose in order to not interfere with the cluster formation). I suppose the FD would need to be instructed / tweaked so as to be more lenient towards seed nodes that have quite a bit of concurrent traffic due to the joining nodes
So what to make out of all of this beyond this experiment? I’m hoping we will not need a 10000 node Akka/Rapid Cluster for real-time contact tracing and I’m not sure there will ever be a use-case for a cluster that big. That is, I also see a few benefits for smaller clusters:
- faster partition resolution. Since dissemination is deterministic the overall time it takes for a cluster to detect, agree upon and resolve a partition (or a failed node, or a set of failed nodes) is smaller than with gossip-based approaches
- better suited for cloud environments. Networking conditions can be flaky there and even if they’re not that flaky, the entire modus operandi of containerized / serverless applications where reconfiguration happens behind the scenes calls for membership protocols optimized for quick decision making. Instead of announcing in advance that a member is leaving gracefully, the membership protocol should just be able to react to its departure quickly. So in this type of environment Rapid’s multi-node cut detector provides a much stronger and deterministic guarantee than using arbitrary timeouts, leading to reduced resolution times. I want to write another article just about this because I think it is important.
Some things I still have on my list for the next days:
- polish the source code of this proof-of-concept and publish it (see the next paragraph). You can already find the additions to Rapid on the repository
- find a way to plot the 10000 node run. There’s a few million points to plot and Kibana’s Vega plotter doesn’t seem to ever achieve that. I managed to convince elasticsearch to return that many documents by giving it enough RAM (usually it is limited to 10000), but then the visualization script that runs in the browser doesn’t appear to ever finish.
- finish the ongoing pull requests for Rapid, in particular the simplified JOIN protocol as well as the anti-entropy mechanism (by providing also a “recovery” variant)
- wrap up this sabbatical and get back to doing some paid work
Finally, many thanks to Lalith Suresh for taking the time to answer to my questions about the protocol and providing pointers in the right direction!
Show me the code!
- changes to Akka are on this branch
- the latest version of Rapid with the changes described in this article are on this branch. I still need to fix flakiness in a few of the tests though
- finally, the experimental setup and all the instructions to run this are in this repository